学习的是https://www.bilibili.com/video/BV1HyWxzQE7K?spm_id_from=333.788.player.switch&vd_source=0ea1552687da3b191a212f42633ae406提供的教学视频,PSQL的12版本。基本内容应该不会差太多,如果有区别,我会直接记下最新操作的笔记。
1. Postgresql和MySQL的对比

2. postgresql安装
安装过程省略,推荐在linux上进行安装使用,并且Linux最好是最小安装,不要带GUI界面的那种。在安装完成之后,由于postgresql不推荐使用root管理,它会默认给你创建一个用户:postgres。所以在玩PGSQL之前,要先切换到postgres用户。
xxxxxxxxxx81# 切换到 postgres 用户,密码 !@#qaz12 。su命令是 switch user的简写。2su postgres34# 进入到postgresql的客户端命令行界面5psql67#查看有哪些库,在命令行中输入8\l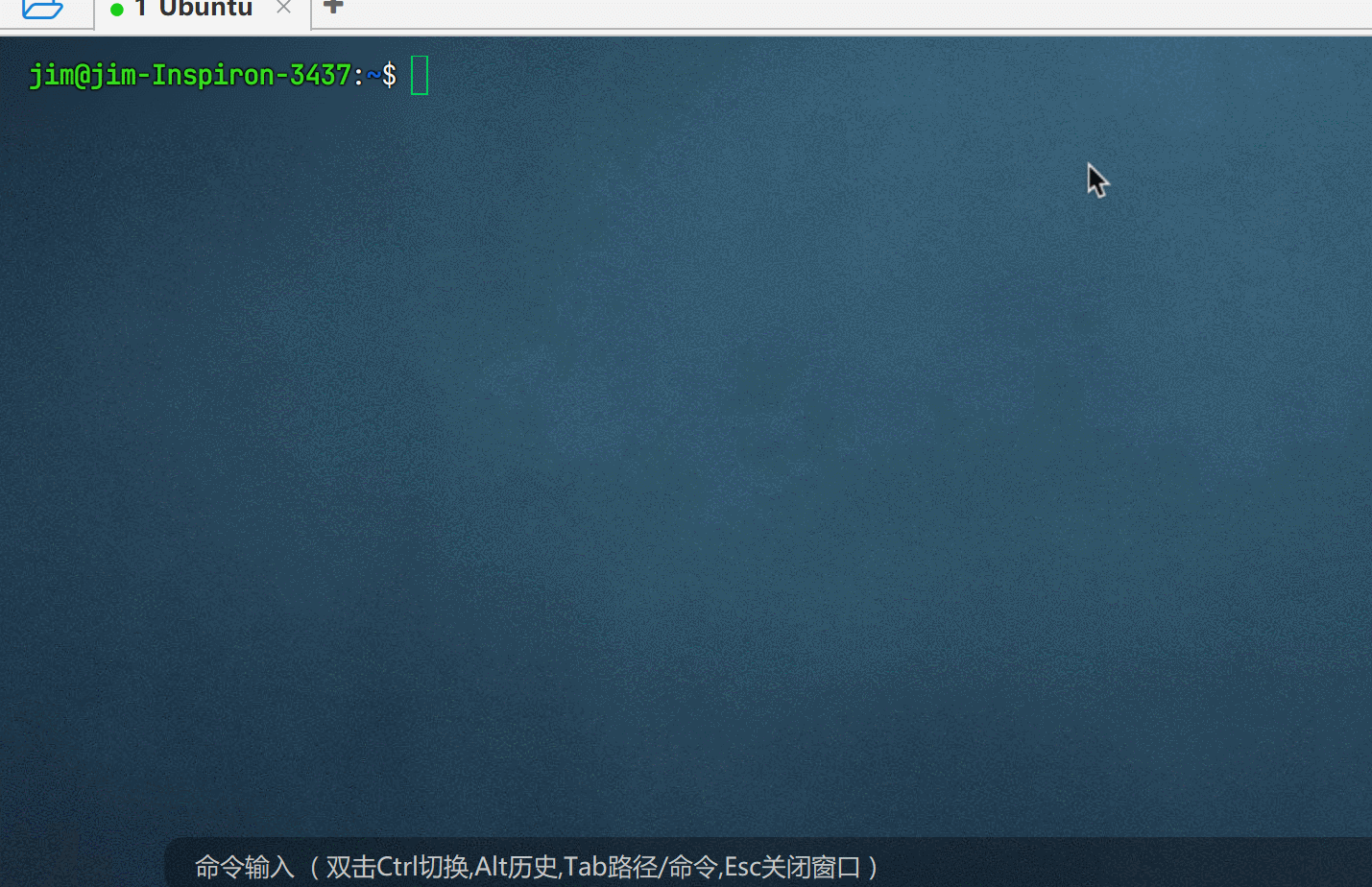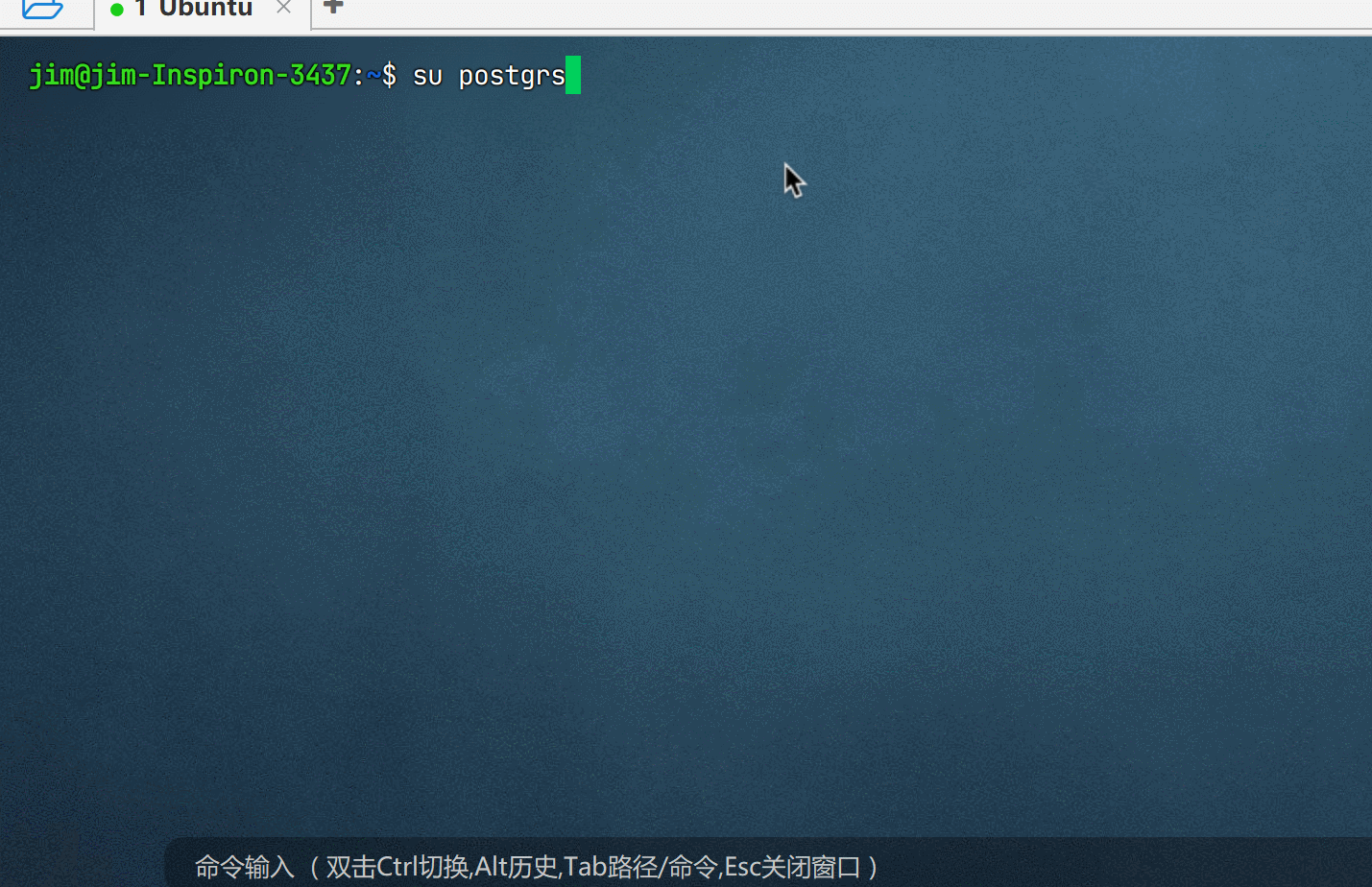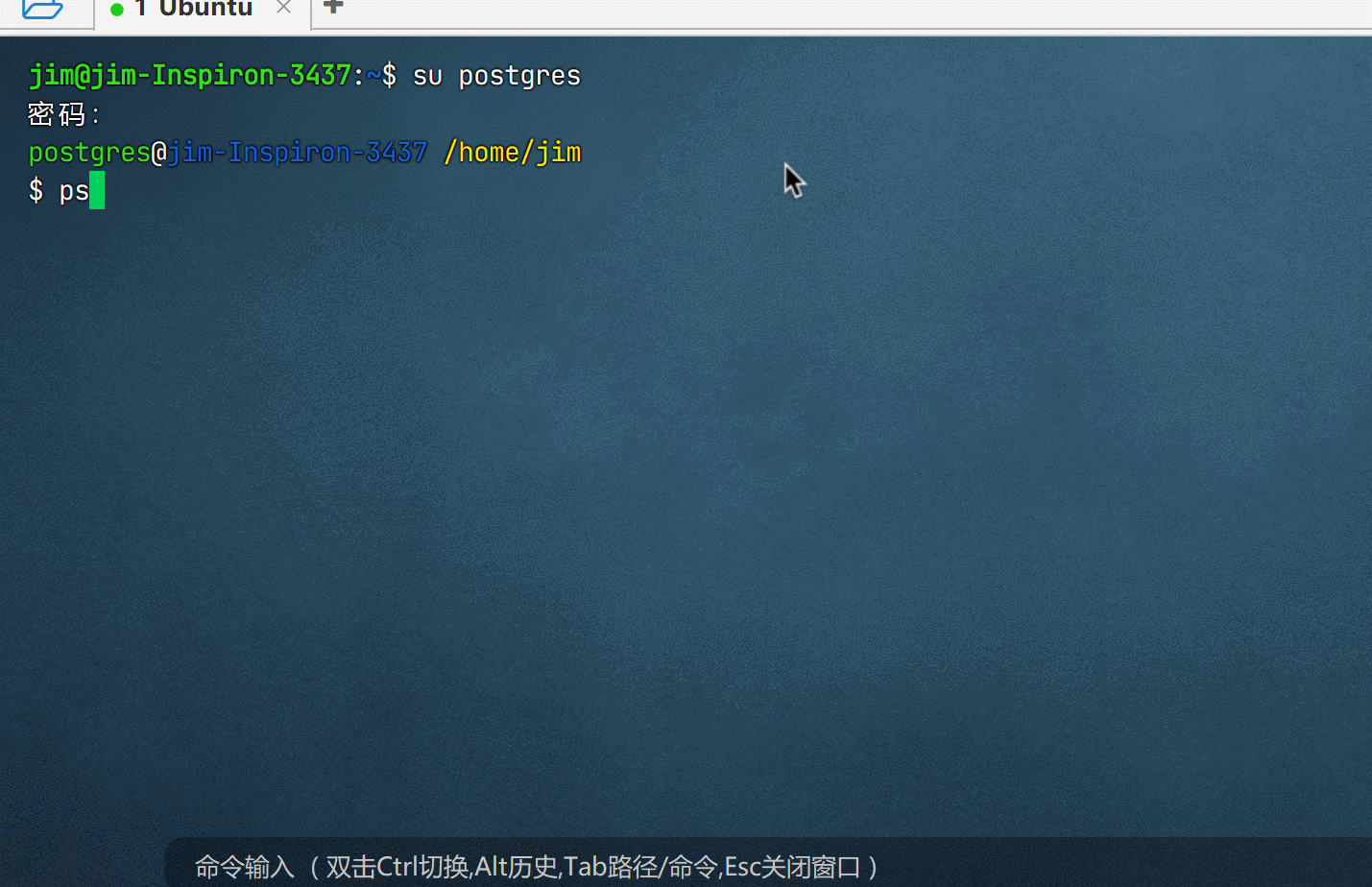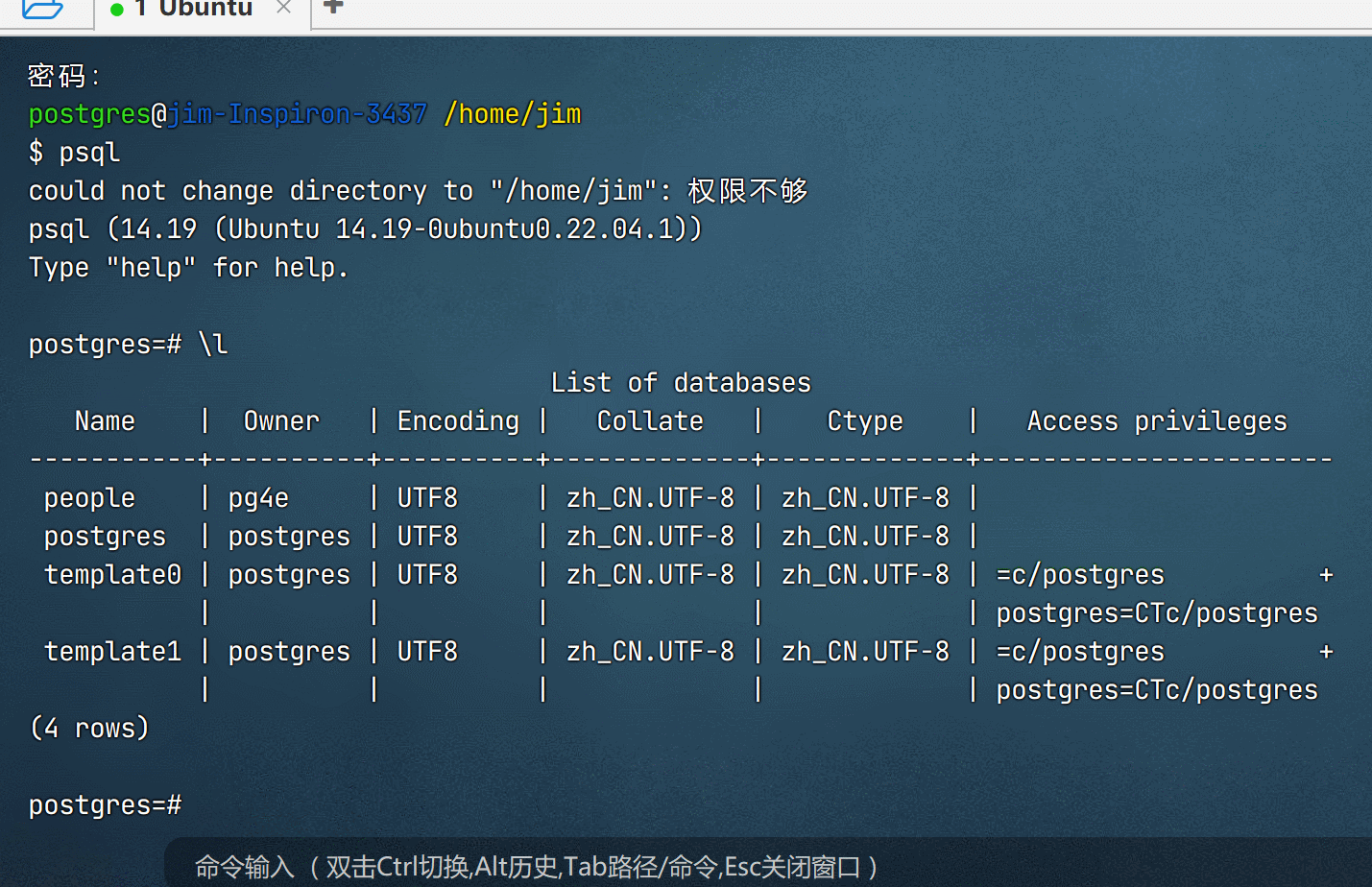
3. postgresql配置
postgresql的主要配置放在数据目录(data/)下,postgresql.conf和pg_hba.conf。
/etc/postgresql/14/main/pg_hba.conf
/etc/postgresql/14/main/postgresql.conf
3.1 远程连接配置
主用户:
xxxxxxxxxx11sudo nano /etc/postgresql/14/main/pg_hba.conf然后在文件底部加入,这表示允许任意地址的所有用户连接所有数据库。修改后保存文件。
xxxxxxxxxx11host all all 0.0.0.0/0 md5然后编辑:
xxxxxxxxxx11sudo nano /etc/postgresql/14/main/postgresql.conf将里面的listen_addresses改为*:
xxxxxxxxxx11listen_addresses = '*'保存文件后重启postgresql:
xxxxxxxxxx11sudo systemctl restart postgresql3.2 日志配置
为什么要配置日志?
✅ 1. SQL 报错很难查
例如你的应用报:
xxxxxxxxxx11syntax error at or near “FROM”
但你不知道是哪一条 SQL 出错。 开启 SQL 日志后,你能看到完整 SQL。
✅ 2. 性能调优离不开日志
你可以找出:
- 慢 SQL(执行 1s 以上的操作)
- 锁阻塞(哪个 SQL 卡住了)
- 全表扫描
- 数据库连接数满了
- 自动 VACUUM 或 autovacuum 卡住
所有这些都必须从日志判断。
✅ 3. 安全审计
可以记录:
- 谁登录数据库
- 什么 IP
- 执行了哪些管理指令
- 失败的登录尝试
这是企业应用、线上系统必备的。
⚠️ 结论:不配置日志 = 出问题没地方查
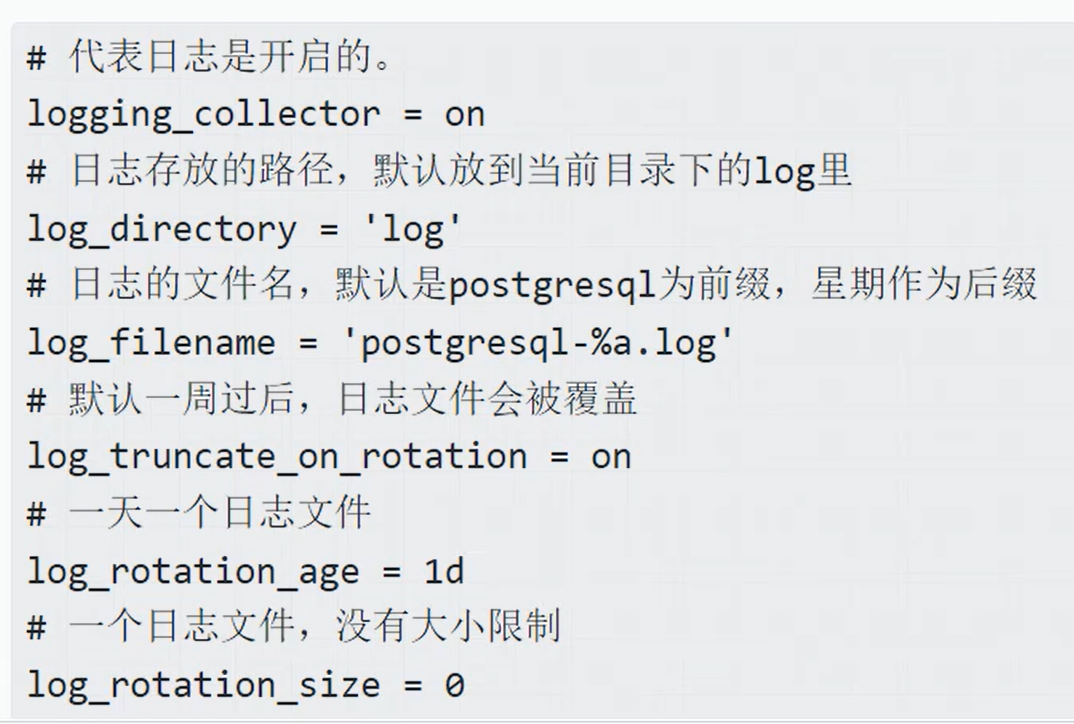
xxxxxxxxxx11sudo nano /etc/postgresql/14/main/postgresql.conf按照下面来配置即可:

postgresql默认情况下,只保存7天的日志,循环覆盖。下面是参数说明:
4. 基操用户操作
进入到psql命令行之后。
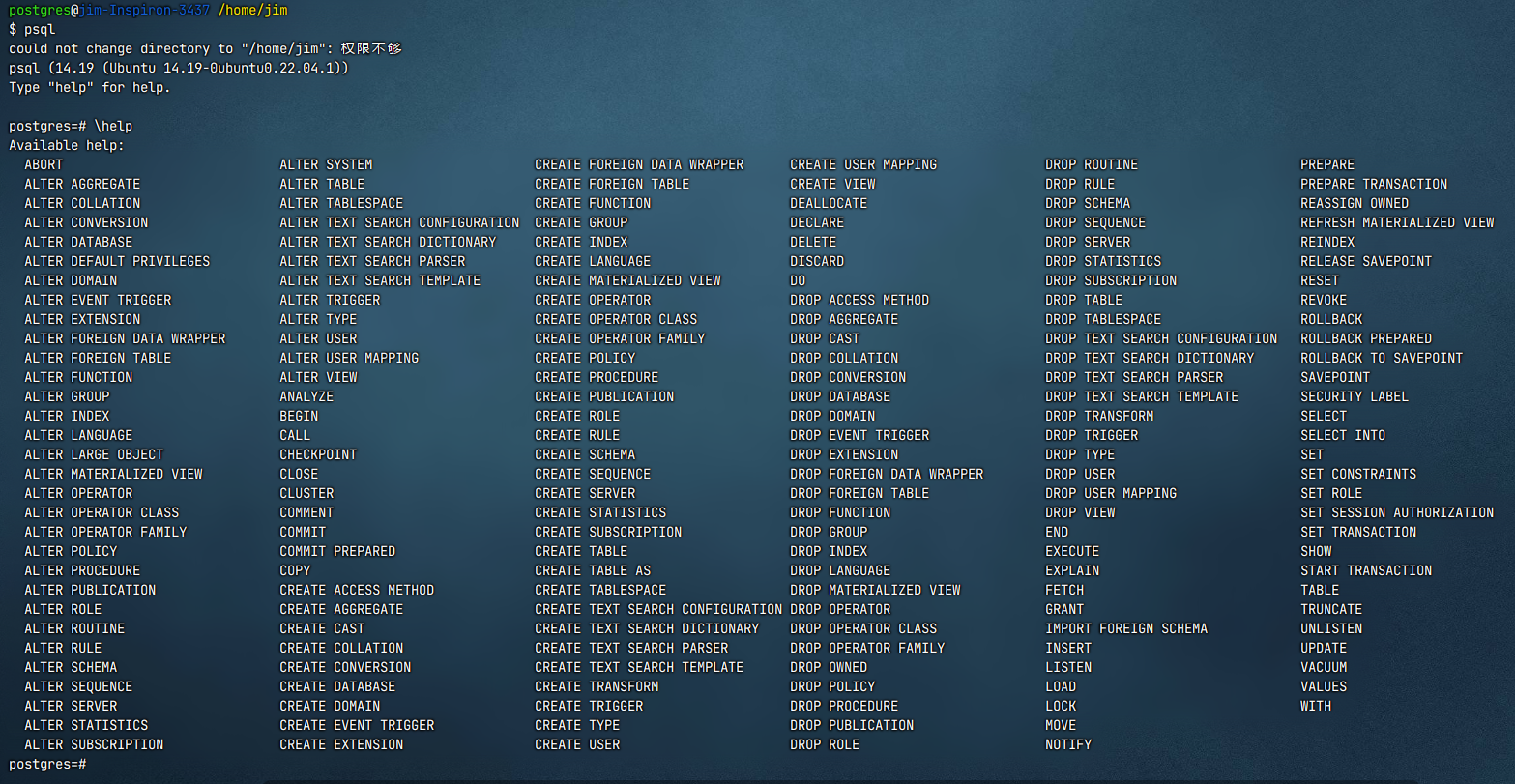
\help,查看数据库级别的命令:
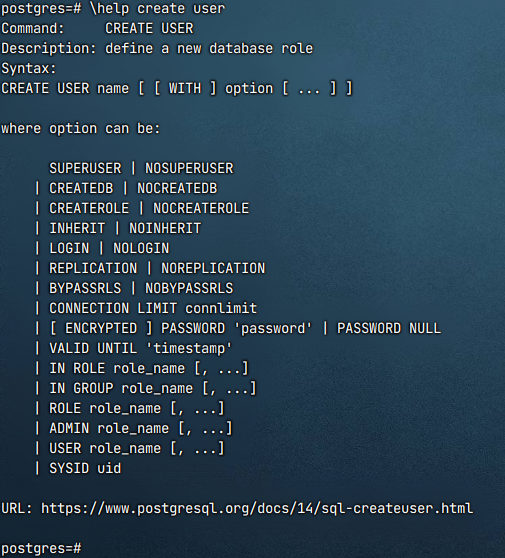
\help 具体的命令,查看具体命令的使用方法,比如说\help create user:
\?,查看服务级别的命令,按q退出这个界面:
\q,退出psql命令行:

\du,查看全部用户:
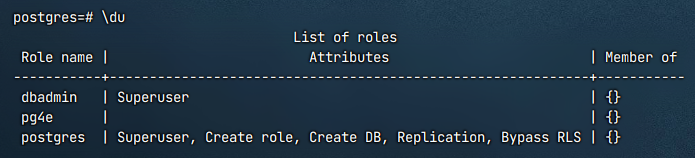
下面是一些实际操作:
创建一个超级管理员用户。
xxxxxxxxxx11create user root with SUPERUSER PASSWORD 'root';
为什么这里的回显是create role呢?我明明是创建了用户啊,原因是从 PostgreSQL 8.1 开始,CREATE USER 只是 CREATE ROLE 的语法糖(别名)。
换句话说:
xxxxxxxxxx11CREATE USER = CREATE ROLE WITH LOGIN
只是默认带上 LOGIN(可以登录数据库) 属性而已。
注意,数据库的用户和我认为的前端网站的登录用户,对于数据库的操作是完全不同的概念。
数据库用户是数据库内部的账号,用来:
- 连接数据库(LOGIN)
- 读/写/删/改数据
- 管理数据库对象(表、索引、schema)
- 控制权限与安全
📌 DB 用户是给后端/服务用的,不是给网站会员用的。下节课说的用户权限,指的是DB用户的权限,指的是可以直接连接这个数据库后的操作权限。
网站用户是你的网站/应用里的普通用户:
- 注册 / 登录
- 拥有自己的账号资料
- 角色:普通用户 / VIP / 管理员
- 权限:浏览、下单、评论、点赞等
- 存在于你数据库的某个业务表中,比如 users 表里面,加上几个关联表。
- 权限由应用层控制,比如说判断用户的角色,角色也有roles表,然后根据角色来判断是否能够增删改查。
项目 数据库用户(DB User) 网站用户(App User) 定义 PostgreSQL 内部的账号 存在 users 表里的业务账号 用于 系统访问数据库 用户访问网站 数量 很少 很多 控制权限 SQL 权限 应用代码 不能互相替代 ✔ ✔
5. 基操权限操作和小任务
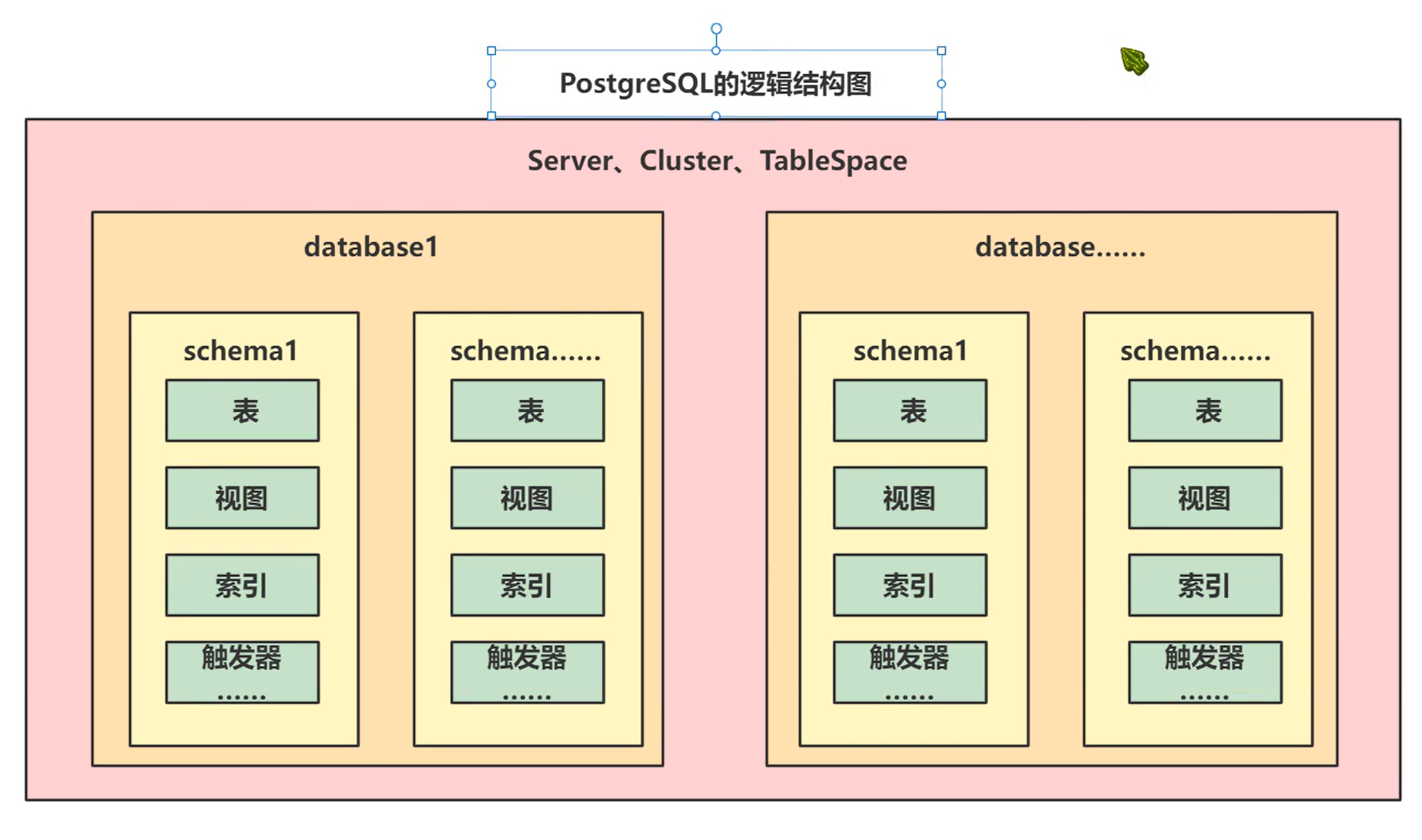
PGSQL的逻辑结构

这部分的内容还是蛮重要的,因为数据安全的重要性不言而喻。但是这部分先不用管,因为命令很简单,到时候搜索即可。
postgresql的逻辑结构:
我们用最直观的方式,把 PostgreSQL 的逻辑结构从“大到小”一层一层讲清楚,你看完就彻底明白了。PostgreSQL 逻辑结构全景图(从大到小)
层级 名称 说明 举个生活中的比喻 1. 整个 PostgreSQL 服务 集群(Cluster) 你启动一个 PostgreSQL 服务(一个端口 5432),它就是一个集群 一整个学校 2. 集群下面有很多 数据库(Database) 集群里可以创建很多个数据库,彼此数据完全隔离 学校里有许多独立的教学楼(文科楼、理科楼) 3. 每个数据库里面有 Schema(模式) 一个数据库里又可以再划分很多 schema,相当于子命名空间 每栋教学楼里有很多教室(schema) 4. Schema 里面放 对象(表、视图、函数、序列等) 真正的表、视图、函数都放在某个 schema 里 教室里放课表、黑板、学生(表、数据) 下面用一张图帮你记住(文字版):
xxxxxxxxxx171一个 PostgreSQL 实例(Cluster)2├── 数据库1:company_db3│ ├── schema: public ← 默认就有的4│ │ ├── 表: users5│ │ ├── 表: orders6│ │ └── 视图: vip_customers7│ ├── schema: hr ← 自己建的8│ │ └── 表: employees9│ └── schema: finance10│ └── 表: salary11│12├── 数据库2:test_db13│ ├── schema: public14│ │ └── 表: test_table15│ └── schema: dev16│17└── 数据库3:postgres(系统默认数据库)每个层级最核心的要点
层级 关键点(你一定要记住) Cluster 一个 PostgreSQL 服务进程(一个端口)就是一个集群,全局共享一套用户(角色)和 tablespace Database 数据完全隔离!不同数据库之间的表、函数同名也不冲突;连接时必须指定连哪个数据库(psql -d company_db) Schema 只是命名空间,不隔离数据!同一个数据库里不同 schema 的表可以互相 join;全路径是 database.schema.table Table 等对象 真正存放数据的地方,必须属于某个 schema 实际工作中最常用的路径写法当你写 SQL 时,完整对象名是这样写的:
xxxxxxxxxx41-- 格式: 数据库名 . schema名 . 对象名2SELECT * FROM company_db.public.users; -- 跨数据库要用 dblink 扩展3SELECT * FROM public.users; -- 省略数据库(当前连接的数据库)4SELECT * FROM hr.employees; -- 省略 public,用自己的 schema再举一个真实项目的典型结构(强烈推荐你也这么用)
xxxxxxxxxx121-- 1. 创建业务数据库2CREATE DATABASE shop;34-- 2. 连接到 shop 数据库后,创建几个 schema5CREATE SCHEMA auth; -- 存放跟认证相关的表6CREATE SCHEMA order_sys; -- 订单系统7CREATE SCHEMA payment; -- 支付相关8CREATE SCHEMA report; -- 报表、统计视图910-- 3. 建表时都指定 schema11CREATE TABLE order_sys.orders (...);12CREATE TABLE payment.records (...);这样做的好处:
- 表多了也不乱,几百张表一眼就能看出属于哪个模块
- 不同团队可以分别管理自己的 schema
- 以后要迁移某个模块的数据,只需要 dump 对应 schema 就行
总结一句话记住了:PostgreSQL 逻辑结构只有 4 层: 集群 → 多个数据库(完全隔离) → 每个数据库里多个 schema(命名空间) → schema 里放表、视图、函数等。相当于: 一个 PostgreSQL 服务 = 一所大学 多个数据库 = 多栋教学楼(楼和楼之间完全不联通) 多个 schema = 每栋楼里的不同教室分区 表 = 教室里的课桌和学生搞清楚这四层关系后,你再看任何 PostgreSQL 项目结构都不会懵了!
下面是在一个项目中使用postgresql的过程,从中可以看到postgresql的各种概念的使用。
- 本地/服务器上创建数据库、用户
- 推荐的数据库 & schema 结构
- 初始化表(迁移方式)
- Next.js 14(App Router)项目里怎么安全、优雅地连接和操作 PostgreSQL
- 生产环境部署注意事项(Vercel / 自建服务器)
一、PostgreSQL 端:完整建库建用户脚本(直接拷贝执行)
xxxxxxxxxx311-- 1. 登录 postgres 超级用户(本地通常是 postgres 或你的系统用户)2sudo -u postgres psql34-- 2. 创建专门给这个 Next.js 项目用的数据库用户(建议不直接用 postgres)5CREATE ROLE myapp_user WITH LOGIN PASSWORD 'your_strong_password_here';67-- 3. 创建业务数据库,推荐让应用用户直接做 owner(最省事权限最大)8CREATE DATABASE myapp_prod9OWNER myapp_user10ENCODING 'UTF8'11LC_COLLATE 'en_US.UTF-8'12LC_CTYPE 'en_US.UTF-8'13TEMPLATE template0;1415-- 4. 连接到刚创建的数据库16\c myapp_prod1718-- 5. 创建常用的 schema(强烈推荐按模块分),如果不创建,默认是放在public这个schema里面19CREATE SCHEMA auth AUTHORIZATION myapp_user;20CREATE SCHEMA core AUTHORIZATION myapp_user;21CREATE SCHEMA billing AUTHORIZATION myapp_user;22CREATE SCHEMA analytics AUTHORIZATION myapp_user;2324-- 6. 给 public schema 收回默认权限(安全最佳实践,从 PG13 起默认已经这样了)25REVOKE CREATE ON SCHEMA public FROM PUBLIC;26-- 如果你完全不用 public,可以直接删掉里面的默认权限2728-- 7. (可选)创建扩展,很多项目都会用到29CREATE EXTENSION IF EXISTS "uuid-ossp"; -- uuid_generate_v4()30CREATE EXTENSION IF EXISTS "pgcrypto"; -- crypt(), gen_salt()31CREATE EXTENSION IF EXISTS "citext"; -- 不区分大小写的文本类型二、推荐的表结构示例(用迁移工具管理,后面会讲)
xxxxxxxxxx201-- 示例:users 表放在 auth schema2CREATE TABLE auth.users (3id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),4email CITEXT UNIQUE NOT NULL,5email_verified BOOLEAN DEFAULT false,6password_hash TEXT,7name TEXT,8avatar_url TEXT,9created_at TIMESTAMPTZ DEFAULT NOW() NOT NULL,10updated_at TIMESTAMPTZ DEFAULT NOW() NOT NULL11);1213-- 示例:orders 表放在 core schema14CREATE TABLE core.orders (15id BIGSERIAL PRIMARY KEY,16user_id UUID NOT NULL REFERENCES auth.users(id),17status TEXT NOT NULL DEFAULT 'pending',18total_cents INTEGER NOT NULL,19created_at TIMESTAMPTZ DEFAULT NOW()20);三、Next.js 项目端完整配置(Next.js 14 App Router 推荐做法 2025 年版)1. 安装依赖(2025 年最推荐组合)
xxxxxxxxxx31npm install prisma @prisma/client2# 或者如果你不想用 Prisma,也可以用3npm install pg drizzle-orm @neondatabase/serverless下面分别给出 Prisma(最推荐) 和 Drizzle(轻量) 两套方案,任选其一。方案 A:Prisma(99% 新项目选这个)
xxxxxxxxxx11npx prisma init --datasource-provider postgresql
- .env 文件(本地和生产都放这里)
xxxxxxxxxx51# 本地开发2DATABASE_URL="postgresql://myapp_user:your_strong_password_here@localhost:5432/myapp_prod?schema=public"34# 生产(推荐用 Neon / Supabase / Railway / AWS RDS)5DATABASE_URL="postgresql://myapp_user:xxxxxx@ep-xxxxx.us-east-2.aws.neon.tech/myapp_prod?sslmode=require"
- prisma/schema.prisma(关键:多 schema 配置)
xxxxxxxxxx351generator client {2provider = "prisma-client-js"3}45datasource db {6provider = "postgresql"7url = env("DATABASE_URL")8// 关键!!告诉 Prisma 你用了多个 schema9schemas = ["auth", "core", "billing", "analytics"]10}1112model User {13id String @id @default(uuid()) @db.Uuid14email String @unique @db.Citext15emailVerified Boolean @default(false) @map("email_verified")16passwordHash String? @map("password_hash")17name String?18avatarUrl String? @map("avatar_url")19createdAt DateTime @default(now()) @map("created_at")20updatedAt DateTime @default(now()) @updatedAt @map("updated_at")2122@@schema("auth")23}2425model Order {26id BigInt @id @default(autoincrement())27userId String @db.Uuid28status String @default("pending")29totalCents Int @map("total_cents")30createdAt DateTime @default(now()) @map("created_at")3132user User @relation(fields: [userId], references: [id])3334@@schema("core")35}
- 迁移命令(每次改 schema 后执行)
xxxxxxxxxx81# 开发时实时生成 client2npx prisma generate34# 创建并执行迁移5npx prisma migrate dev --name init67# 生产环境8npx prisma migrate deploy
- 在 Next.js 中使用(lib/prisma.ts)
xxxxxxxxxx131import { PrismaClient } from '@prisma/client'23const globalForPrisma = global as unknown as { prisma: PrismaClient }45export const prisma =6globalForPrisma.prisma ||7new PrismaClient({8log: process.env.NODE_ENV === 'development' ? ['query', 'error', 'warn'] : ['error'],9})1011if (process.env.NODE_ENV !== 'production') globalForPrisma.prisma = prisma1213export default prisma
- 在 Server Component / Route Handler / Server Action 里随便用
xxxxxxxxxx91// app/api/users/route.ts2import prisma from '@/lib/prisma'34export async function GET() {5const users = await prisma.user.findMany({6select: { id: true, email: true, name: true }7})8return Response.json(users)9}四、生产部署最重要几件事(不能忘!)
项目 推荐做法 数据库托管 Neon.tech(免费层超强) / Supabase Postgres / Railway / AWS RDS 环境变量 Vercel → Project Settings → Environment Variables 里加 DATABASE_URL SSL 生产必须强制 sslmode=require 连接池 Vercel/Serverless 环境必须用 PgBouncer 或 Neon 的 serverless driver Prisma 加速 推荐开启 Prisma Accelerate(连接池 + 边缘缓存) 敏感密码 永远不要写死,用 Vercel / Railway 的加密环境变量 备份 Neon 自动 PITR,Supabase 也有自动备份 五、完整一步步操作清单(直接照着做就行)
- 装好 PostgreSQL(本地开发)或注册 Neon/Supabase(推荐)
- 执行上面第一段 SQL 创建用户、数据库、schema
- 创建 Next.js 项目 npx create-next-app@latest myapp --ts
- 装 Prisma → prisma init → 配置 schema.prisma
- 写完模型 → npx prisma migrate dev --name init
- 开发中使用,部署时只跑 npx prisma migrate deploy
- 把 DATABASE_URL 填到 Vercel 环境变量 → 部署
6. pgAdmin图形化界面连接和基本操作
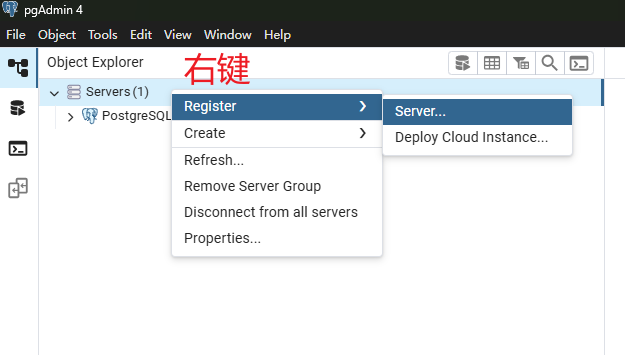
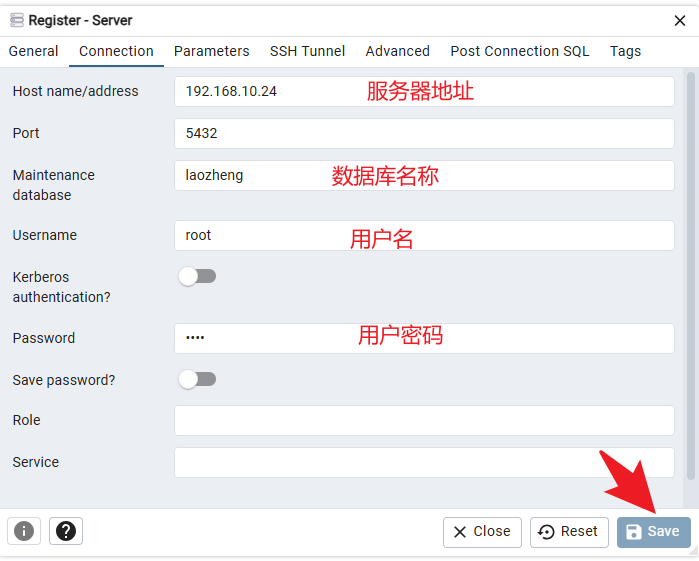
连接成功之后,可以打开命令行:
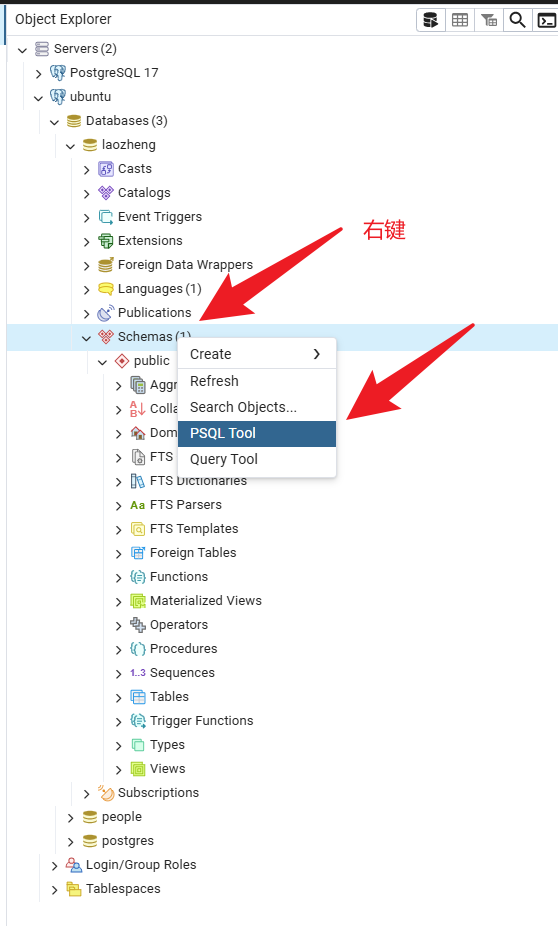
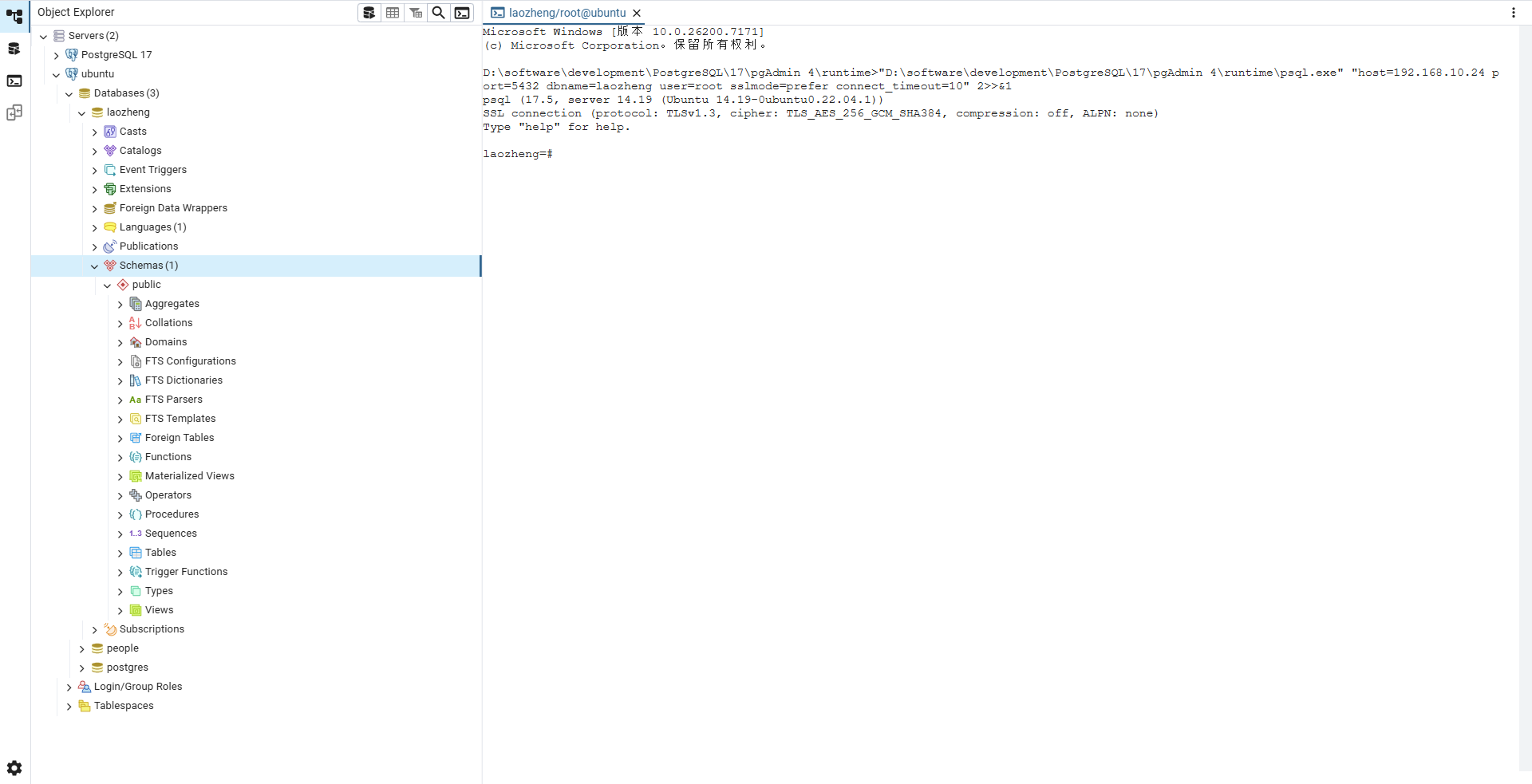
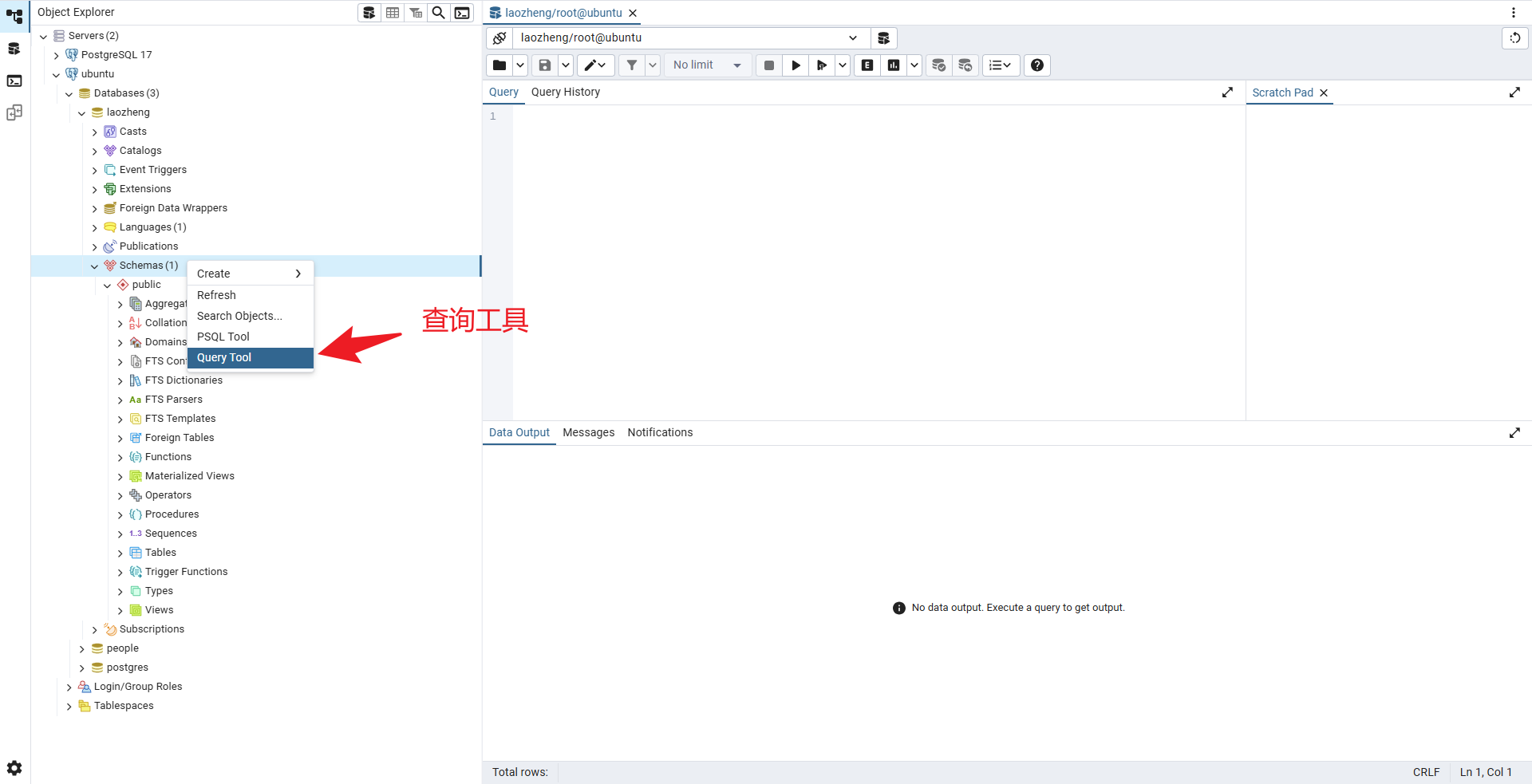
打开查询工具:
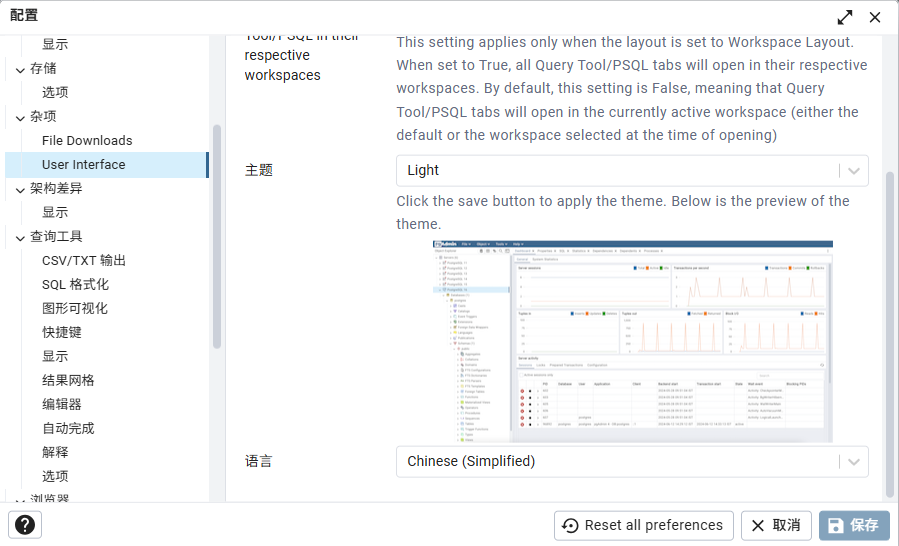
显示中文界面
7. 数据类型
90%情况下,只需要关注数字、字符串、时间这三种类型即可。
总结:你日常只需要记住这几行就行
xxxxxxxxxx121id UUID PRIMARY KEY DEFAULT uuid_generate_v4()2id BIGSERIAL PRIMARY KEY3email CITEXT UNIQUE NOT NULL4password_hash TEXT5amount NUMERIC(12,2)6total_cents INTEGER7content TEXT8metadata JSONB DEFAULT '{}'9tags TEXT[] DEFAULT '{}'10created_at TIMESTAMPTZ DEFAULT NOW()11updated_at TIMESTAMPTZ DEFAULT NOW()12deleted_at TIMESTAMPTZ2025 年实际项目中 99% 情况你只需要记住下面这 10 个就够了(生产推荐组合)
| 场景 | 推荐类型 | 为什么 |
|---|---|---|
| 主键 | uuid 或 bigserial | uuid 分布式安全,bigserial 最简单 |
| 用户 ID | uuid | 防止泄露用户数量,分布式友好 |
| 自增 ID | bigserial | 简单粗暴,顺序递增 |
| 金额 | numeric(12,2) 或 integer(存分) | 绝对精确,金融级 |
| 文本 | text | 别再用 varchar 了,性能一样,没长度限制 |
| 邮箱 | citext | 自动忽略大小写,不用再 upper(email) |
| 时间 | timestamptz | 自动带时区,存 UTC,全球通用 |
| 软删除时间 | timestamptz | deleted_at TIMESTAMPTZ NULL |
| 状态/枚举 | text + check 约束 | 比 enum 类型灵活,改起来不锁表 |
| 配置/扩展字段 | jsonb | 什么都能存,还能建 GIN 索引 |
| 标签、角色列表 | text[] 或 jsonb | 数组简单,复杂结构用 jsonb |
枚举类型怎么写(推荐替代方案)不要用 PostgreSQL 原生 enum(改起来很麻烦),改用 check 约束:
xxxxxxxxxx61CREATE TABLE core.orders (2 id BIGSERIAL PRIMARY KEY,3 status TEXT NOT NULL DEFAULT 'pending' CHECK (status IN (4 'pending', 'paid', 'shipped', 'completed', 'cancelled', 'refunded'5 ))6);详细说明:
| 大类 | 数据类型 | 常见写法 / 示例 | 什么时候用(一句话记住) |
|---|---|---|---|
| 数字类型 | smallint | int2 | 极小整数,省空间,范围 -32k ~ +32k |
| integer | int, int4 | 最常用整数,几乎所有 id、计数都用这个 | |
| bigint | int8 | 超大数字,订单号、雪花 ID、金额分等用这个 | |
| smallserial | serial2 | 2字节自增 id(1~32767) | |
| serial | serial4 | 4字节自增,最常用 | |
| bigserial | serial8 | 8字节自增,永远不会用完 | |
| numeric / decimal | numeric(10,2) | 金融级精确小数,金额必用(不要用 float) | |
| real / float4 | real | 单精度浮点,科学计算用 | |
| double precision / float8 | double precision | 双精度浮点,普通科学计算 | |
| 货币类型 | money | money | 已不推荐(有精度问题),改用 numeric(12,2) + 分存储 |
| 文本类型 | text | text | 2025 年最推荐!啥都存 text,性能和 varchar 几乎一样,无长度限制 |
| varchar[n] | varchar(255) | 只有在需要限制长度做校验时才用 | |
| char[n] | char(10) | 极少用,定长,基本没人用 | |
| citext | citext | 不区分大小写的 text,非常好用(需 create extension citext;) | |
| 布尔类型 | boolean | bool, true/false | 只有 true / false / null 三种值 |
| 时间类型 | timestamp | timestamp | 不带时区,存本地时间(大部分项目用这个) |
| timestamptz | timestamp with time zone | 带时区,推荐!所有生产项目都用 timestamptz(内部存 UTC) | |
| date | date | 只存日期 | |
| time | time | 只存时间 | |
| timetz | time with time zone | 时间带时区 | |
| interval | interval | 时间间隔,比如 “3 days”、 “2 hours” | |
| UUID | uuid | uuid | 分布式唯一 ID 必备(比 bigint 更安全) |
| JSON | json | json | 存结构化但不经常查的日志、配置 |
| jsonb | jsonb | 2025 年最爱!支持索引、二进制存储、查询超快,所有半结构化数据都用 jsonb | |
| 数组类型 | 任意类型[] | text[], int[], timestamptz[] | 一列存多个值,比如标签、角色列表 |
| 范围类型 | int4range, int8range, tsrange, tstzrange, daterange, numrange | int4range('[1,10]', '[]') | 非常强大,比如价格区间、预约时间段、有效期 |
| 网络地址类型 | inet | inet | 存 IPv4/IPv6 + 子网掩码 |
| cidr | cidr | 存 IP 网段 | |
| macaddr | macaddr | MAC 地址 | |
| 几何类型 | point, line, circle, box, polygon, path, lseg | point(1.5, 2.5) | 做地图、GIS 用(配合 PostGIS 扩展更强) |
| 货币/金额专用 | money → 废弃 | 改用 numeric(12,2) 或 integer(存分) | |
| 特殊类型 | bytea | bytea | 存二进制文件、图片小文件(大文件建议放对象存储) |
| xml | xml | 存 XML(几乎没人用) | |
| bit / bit varying | bit(8), varbit | 位操作 | |
| tsvector / tsquery | tsvector | 全文搜索专用(配合 GIN 索引超快) | |
| hstore | hstore | key-value 键值对(老项目用,现在基本被 jsonb 取代) | |
| ltree | ltree | 树形结构、路径(如 1.2.3.4 表示层级) | |
| int4multirange, etc. | 多段范围(PG14+) | 比如一个用户一天有多个可用时间段 |
8. PGSQL操作
8.1 单引号和双引号
单引号
在PGSQL中,写SQL语句时,单引号 ('...') 用于界定 字符串常量 (String Literals),也就是 SQL 语句中用作数据的文本值。
核心规则:
- 界定数据: 任何作为数据插入、更新或比较的文本,都必须用单引号括起来。
- 数据类型: 只要是用单引号括起来的值,PostgreSQL 会尝试将其解析为适合该上下文的数据类型(如
VARCHAR,TEXT,DATE,TIMESTAMP)。
示例:
xxxxxxxxxx81-- 示例 1: 字符串数据2INSERT INTO products (name) VALUES ('笔记本电脑'); 34-- 示例 2: 日期/时间数据 (虽然看起来是文本,但会被解析为日期)5SELECT * FROM orders WHERE order_date = '2025-12-01';67-- 示例 3: 在 SELECT 语句中返回一个固定的文本8SELECT 'Hello World' AS message;双引号
双引号 ("...") 用于界定 标识符 (Identifiers),即数据库对象(表名、列名、模式名、函数名等)的名称。
核心规则:
- 区分大小写: 这是双引号最关键的作用。在 PostgreSQL 中,如果一个标识符没有被双引号括起来,它会被自动转换为 小写。如果使用双引号,则名称会严格区分大小写,并保留你提供的原样。
- 允许使用非法字符: 双引号允许你在标识符中使用空格、特殊字符或 SQL 保留字。
示例:
A. 默认行为 (不使用双引号)
xxxxxxxxxx91CREATE TABLE MyTable (2 FirstName VARCHAR(50)3);45-- 实际创建的表名是: mytable6-- 实际创建的列名是: firstname78-- 查询时必须使用小写 (或不使用双引号)9SELECT firstname FROM mytable; B. 使用双引号 (强制区分大小写)
xxxxxxxxxx71CREATE TABLE "MyTable" (2 "First Name" VARCHAR(50), -- 允许空格3 "ORDER" INTEGER -- 允许使用 SQL 保留字4);56-- 查询时必须精确使用双引号和原先的大小写/空格7SELECT "First Name" FROM "MyTable" WHERE "ORDER" > 10;最佳实践: 强烈建议不要在标识符中使用双引号,除非你确实需要使用空格或保留字。遵循小写和下划线的命名约定 (e.g.,
user_account) 可以使你的 SQL 代码更简洁、更具可移植性。
8.2 数据类型转换
方式一:只需要在值的前面,添加上具体的数据类型即可
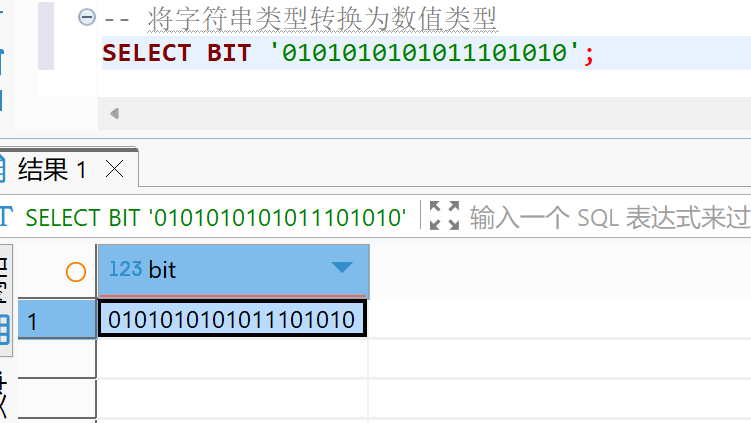
方式二:在具体值后面,添加上 ::类型 来指定
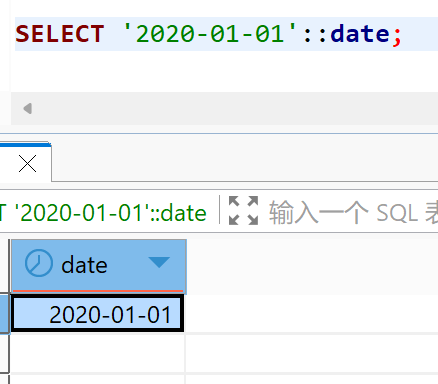
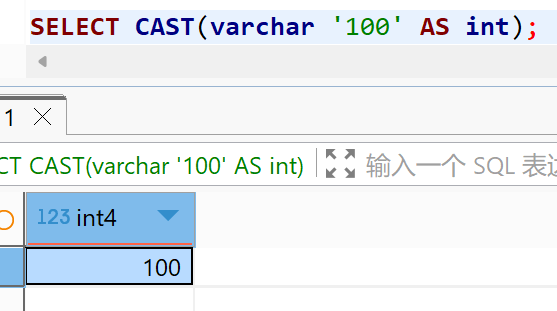
完整写法:
8.3 布尔类型
有三种值:true、false、null。
灵活的输入值 (Valid Literal Values)
这是 PostgreSQL 与其他数据库最大的不同点之一。它非常宽容,除了标准的 TRUE/FALSE,还接受多种字符串表示形式(不区分大小写)。
| 状态 | 标准 SQL 写法 | 允许的字符串写法 (不区分大小写) | 允许的数字写法 |
|---|---|---|---|
| 真 (True) | TRUE | 't', 'true', 'y', 'yes', 'on' | '1' |
| 假 (False) | FALSE | 'f', 'false', 'n', 'no', 'off' | '0' |
注意: 使用字符串形式(如 'yes')时,必须加单引号;使用关键字 TRUE 或 FALSE 时不需要引号。
如果要使用字符串或者数字写法来当作布尔值,select的时候要进行转换才能称为boolean类型
xxxxxxxxxx81-- 整数转布尔 (非0为True,0为False,但在PG中仅0和1能直接转,其他需逻辑判断)2SELECT 1::BOOLEAN; -- 结果: true3SELECT 0::BOOLEAN; -- 结果: false4SELECT 'yes'::BOOLEAN; -- 结果: true56-- 布尔转整数 (需要显式转换)7SELECT (TRUE)::INTEGER; -- 结果: 18SELECT (FALSE)::INTEGER; -- 结果: 0推荐写法 (简洁)
不需要写 = TRUE 或 = FALSE。
xxxxxxxxxx51-- 查找活跃用户 (is_active 为真)2SELECT * FROM users WHERE is_active;34-- 查找非活跃用户 (is_active 为假)5SELECT * FROM users WHERE NOT is_active;处理 NULL 值 (三值逻辑)
这是布尔类型最容易出错的地方。NULL 既不是 TRUE 也不是 FALSE。
如果你想查询“所有未明确被禁止”的用户(即包含 TRUE 和 NULL,但不包含 FALSE),你需要使用 IS NOT 语法:
xxxxxxxxxx51-- 包含 TRUE 和 NULL 的行2SELECT * FROM users WHERE is_active IS NOT FALSE;34-- 包含 FALSE 和 NULL 的行5SELECT * FROM users WHERE is_active IS NOT TRUE;boolean类型在做and or的逻辑操作时,结果有哪些
1. 逻辑与 (AND) 的结果
AND 操作只有在所有输入都为 TRUE 时,结果才为 TRUE。只要有任何一个操作数为 FALSE,结果立即为 FALSE。
| A | B | A AND B | 解释 |
|---|---|---|---|
| TRUE | TRUE | TRUE | 两个条件都满足 |
| TRUE | FALSE | FALSE | 有一个条件不满足 |
| FALSE | FALSE | FALSE | 两个条件都不满足 |
| TRUE | NULL | NULL | 结果取决于 NULL 是否为 TRUE,但我们不知道,所以是未知。 |
| FALSE | NULL | FALSE | 无论 NULL 是 TRUE 还是 FALSE,由于其中一个操作数已经是 FALSE,根据短路原则,结果一定是 FALSE。 |
| NULL | NULL | NULL | 两个都是未知 |
2. 逻辑或 (OR) 的结果
OR 操作只要有一个输入为 TRUE,结果就为 TRUE。只有当所有输入都为 FALSE 时,结果才为 FALSE。
| A | B | A OR B | 解释 |
|---|---|---|---|
| TRUE | TRUE | TRUE | 有一个条件满足 |
| TRUE | FALSE | TRUE | 有一个条件满足 |
| FALSE | FALSE | FALSE | 两个条件都不满足 |
| TRUE | NULL | TRUE | 无论 NULL 是 TRUE 还是 FALSE,由于其中一个操作数已经是 TRUE,根据短路原则,结果一定是 TRUE。 |
| FALSE | NULL | NULL | 结果取决于 NULL 是否为 TRUE,但我们不知道,所以是未知。 |
| NULL | NULL | NULL | 两个都是未知 |
3. 逻辑非 (NOT) 的结果
NOT 操作就是对操作数取反。
| A | NOT A |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| NULL | NULL |
4. 总结与在 WHERE 子句中的应用
理解三值逻辑最重要的一点,在于它如何影响数据库查询中的 WHERE 子句:
WHERE子句只会返回那些其条件表达式计算结果为TRUE的行。
这意味着:
- 如果条件计算结果是
TRUE,则该行被返回。 - 如果条件计算结果是
FALSE,则该行被过滤。 - 如果条件计算结果是
NULL(未知),则该行也被过滤。
最佳实践建议
命名规范: 给布尔字段命名前加上
is_、has_或can_等前缀,这样代码的可读性极高。- ✅
is_visible,has_permission,can_login - ❌
visible,permission,login(容易被误认为是名词或字符串)
- ✅
默认值: 尽量在建表时给布尔字段设置
DEFAULT值(通常是FALSE)。这可以避免在业务逻辑中处理棘手的NULL值。xxxxxxxxxx11is_deleted BOOLEAN NOT NULL DEFAULT FALSE避免使用 CHAR(1) 或 INT: 虽然可以用
0/1或'Y'/'N'来模拟,但使用原生的BOOLEAN类型存储效率更高,且语义更明确,能防止无效数据的插入(例如防止插入'X')。
8.4 数值类型
8.4.1 整型
| 类型名称 | 存储空间 | 最小/最大值范围 (近似值) | 适用场景 |
|---|---|---|---|
| SMALLINT | 2 字节 | 计数较小的标志或状态码、内存占用敏感的巨大表。 | |
| INTEGER | 4 字节 | 亿 | 最常用和推荐的默认选择。适用于大多数 ID、计数和常规数值。 |
| BIGINT | 8 字节 | 巨大的 ID(比如说雪花ID)、高流量表的主键、货币价值、天文数字、系统计数。 |
类型别名:
| 类型名称 (最常用) | 存储空间 | 别名 1 (SQL 标准) | 别名 2 (PostgreSQL 内部/SQL 简写) |
|---|---|---|---|
| SMALLINT | 2 字节 | INT2 | 无 |
| INTEGER | 4 字节 | INT4 | INT |
| BIGINT | 8 字节 | INT8 | 无 |
8.4.2 浮点型
就关注两种类型(本质上就只有一个)
- decimal(n, m):本质就是numeric类型,PGSQL会帮你转换为numeric类型
- numeric(n, m):PGSQL本质的浮点类型
针对浮点类型的数据,就使用 numeric ,不用考虑其它。
语法:NUMERIC(p, s)
NUMERIC 允许您指定精度和标度:
- (Precision,精度): 数字的总位数(小数点左右)。
- (Scale,标度): 小数点右侧的位数。
示例:
xxxxxxxxxx71-- NUMERIC(5, 2)2-- 总共 5 位数字,其中 2 位在小数点后。3-- 范围大致是 -999.99 到 999.994CREATE TABLE finance (5 price NUMERIC(5, 2), 6 tax_rate DECIMAL(4, 3) -- DECIMAL 是 NUMERIC 的别名7);8.4.3 序列
序列是 PostgreSQL 用于生成唯一、有序、自动递增(或递减)的整数的数据库对象。它们是实现自动增长主键的基石。MySQL中的主键自增,是基于auto_increment来实现的,MySQL里面没有序列对象。PGSQL和Oracle十分相似,支持序列:sequence。PGSQL是没有auto_increment的。
序列的定义和核心用途
A. 定义 (What is a Sequence?)
序列是一个独立的数据库对象,它不属于任何表,但可以被任何表或查询引用。它的主要作用是维护一个计数器,并保证在任何时间点,只要调用它,就能返回一个唯一且原子性递增的数值。
B. 核心用途
序列最主要的应用就是作为表的主键 (Primary Key) 生成器,确保每条新插入的记录都有一个独一无二的 ID。
序列的正常构建方式
A. 创建序列
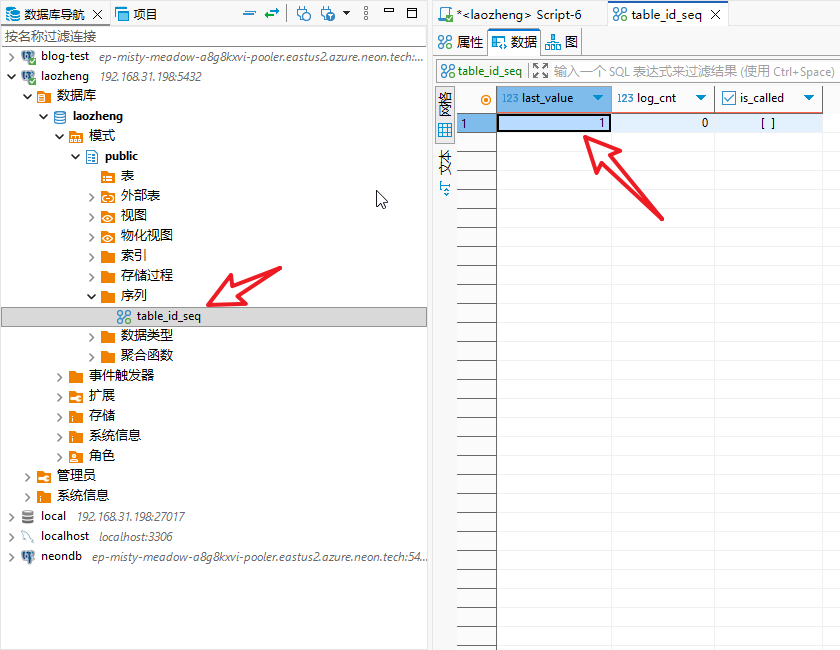
默认情况下,sequence的起始值是0,最大值9223372036854775807,每次nextval递增1。
xxxxxxxxxx11CREATE SEQUENCE table_id_seq;创建之后可以看到:
B. 主要的操作函数
| 函数 | 作用 | 示例 |
|---|---|---|
nextval('seq_name') | 获取并前进:原子性地递增序列,并返回序列的下一个值。 | SELECT nextval('sku_sequence'); |
currval('seq_name') | 获取当前值:返回当前会话中最近一次由 nextval() 取出的值。 | SELECT currval('sku_sequence'); |
setval('seq_name', value) | 设置值:用于手动设置序列的当前值(通常用于迁移数据或重置)。 | SELECT setval('sku_sequence', 5000); |
C. 应用-当作表的主键生成器
xxxxxxxxxx41CREATE TABLE xxx(2 id bigint DEFAULT nextval('table_id_seq'),3 name varchar(16)4);然后执行多次插入语句,就可以看到id是自增的。
xxxxxxxxxx11INSERT INTO xxx (name) VALUES ('xxx');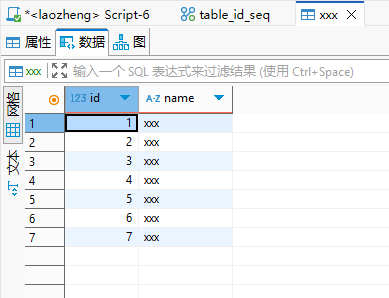
序列的简单构建方式
序列的正常构建方式,需要先专门构建一个序列表。PGSQL提供了序列这种语法糖,可以在声明表结构的时候,直接指定序列的类型即可。
SERIAL 的本质:自动化脚本
SERIAL 本身并不是一种数据类型。它是一个方便的快捷方式(或称“语法糖”),它指示 PostgreSQL 在您创建表时,自动执行三个独立的 SQL 步骤,从而将一列变成自动递增的唯一标识符。
当您执行 CREATE TABLE t (id SERIAL); 时,数据库内部实际执行了以下操作:
| 步骤 | 实际操作 | 对应的 SQL 语句 (以 SERIAL 为例) |
|---|---|---|
| 1. 创建序列 | 自动创建一个新的 序列对象,命名通常是 表名_列名_seq。 | CREATE SEQUENCE table_id_seq START WITH 1 INCREMENT BY 1; |
| 2. 设置默认值 | 将该列的默认值设置为调用新创建的序列的 nextval() 函数。 | ALTER TABLE table ALTER COLUMN id SET DEFAULT nextval('table_id_seq'); |
| 3. 设置类型和约束 | 将该列的数据类型设置为基础的整型,并加上 NOT NULL 约束。 | ALTER TABLE table ALTER COLUMN id TYPE INTEGER NOT NULL; |
核心优势: 您只需要写一行 id SERIAL,PostgreSQL 就为您完成了复杂的序列创建、关联和约束设置工作。
三种 SERIAL 变体
| SERIAL 类型 | 对应基础整型 | 存储空间 | 范围 |
|---|---|---|---|
| SMALLSERIAL | SMALLINT (INT2) | 2 字节 | |
| SERIAL | INTEGER (INT4) | 4 字节 | 亿 |
| BIGSERIAL | BIGINT (INT8) | 8 字节 |
最佳实践选择:
- 默认选择:
SERIAL(INTEGER) 适用于绝大多数应用。 - 高流量/大表: 如果您的表预计会存储超过 20 亿行,或者您想最大化安全范围,请使用
BIGSERIAL。这是很多现代大型系统的推荐。
SERIAL 的重要特性:所有权与依赖性
使用 SERIAL 创建的序列对象与手动创建的序列对象有一个关键区别:所有权 (Ownership)。
A. 自动所有权
当您使用 SERIAL 创建一列时,PostgreSQL 会自动将序列的所有权归属于该表列。
xxxxxxxxxx41CREATE TABLE users (2 user_id BIGSERIAL PRIMARY KEY,3 username VARCHAR(50)4);在这种情况下,序列 users_user_id_seq 归属于 users 表的 user_id 列。
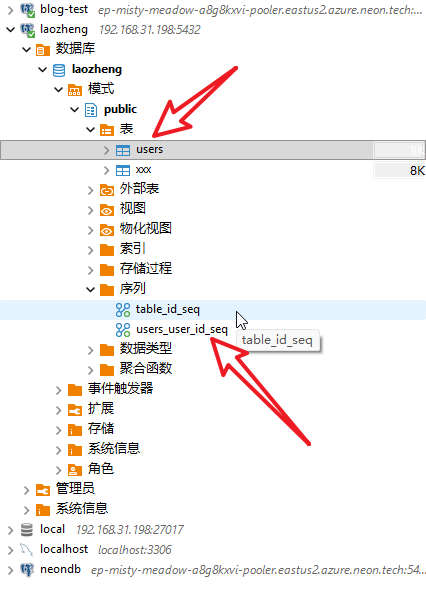
B. 级联删除 (Dependency)
由于所有权关系的存在,序列具有强大的依赖性:
当您删除(
DROP)包含SERIAL列的表时,PostgreSQL 会自动删除关联的序列对象。我试过了,是真的。
这使得管理非常方便,不会在数据库中留下无用的序列垃圾。如果序列是手动创建的,您必须手动删除序列(DROP SEQUENCE)。
C. 序列名称查找
如果您需要检查或修改序列的属性(如手动重置起始值),您需要知道它的名字。PostgreSQL 默认的命名规则是:[表名]_[列名]_seq。
示例:重置序列值
假设您的 users 表因为数据导入导致序列号混乱,需要从 10000 开始:
xxxxxxxxxx51-- 1. 查找序列名称 (通常是 users_user_id_seq)23-- 2. 使用 setval() 函数重置序列的当前值4SELECT setval('users_user_id_seq', 10000, true); 5-- 第三个参数 'true' 表示下一个 nextval() 调用将返回 10001简单构建方式和正常构建方式的区别
| 操作 | SERIAL 语法 | 显式序列 (手动) |
|---|---|---|
| 创建表 | CREATE TABLE t (id SERIAL); | CREATE TABLE t (id INTEGER NOT NULL DEFAULT nextval('t_id_seq')); |
| 序列对象 | 自动创建,例如 t_id_seq | 必须手动创建:CREATE SEQUENCE t_id_seq; |
| 依赖性 | 序列依赖于列,删除列会删除序列。 | 序列独立存在,需要手动删除 (DROP SEQUENCE)。 |
8.4.4 数值类型的常见操作
1. 基础数学运算符 (Arithmetic Operators)
这是最常用的一组操作,遵循标准的数学规则。
| 运算符 | 名称 | 示例 (A = 10, B = 3) | 结果 (INTEGER) |
|---|---|---|---|
+ | 加法 | A + B | 13 |
- | 减法 | A - B | 7 |
* | 乘法 | A * B | 30 |
/ | 除法 | A / B | 3 (整型除法,舍弃小数) |
% | 求余 (模运算) | A % B | 1 |
^ | 幂运算 | A ^ 2 | 100 |
⚠️ 注意整型除法:
当使用两个整型(INTEGER 或 BIGINT)进行 / 除法时,结果仍然是整型,任何小数部分都会被截断 (truncated),而不是四舍五入。
如果需要精确的浮点数结果,请确保至少有一个操作数是浮点类型:
SELECT 10.0 / 3;
2. 比较和逻辑操作 (Comparison and Logic)
这些操作返回一个布尔值 (TRUE, FALSE, 或 NULL),主要用于 WHERE 或 HAVING 子句进行过滤。
| 运算符 | 名称 | 示例 |
|---|---|---|
= | 等于 | WHERE price = 19.99 |
< | 小于 | WHERE age < 18 |
> | 大于 | WHERE score > 90 |
<= | 小于等于 | WHERE count <= 100 |
>= | 大于等于 | WHERE quantity >= 10 |
!= 或 <> | 不等于 | WHERE status != 0 |
BETWEEN | 在...之间 (含边界) | WHERE value BETWEEN 10 AND 20 |
IN | 在列表中 | WHERE id IN (1, 5, 8) |
3. 聚合函数 (Aggregate Functions)
聚合函数用于对一组行(通常是分组后的数据)进行计算,并返回一个单一的汇总值。
| 函数 | 作用 | 示例 |
|---|---|---|
SUM() | 求和 | SELECT SUM(salary) FROM employees; |
AVG() | 平均值 | SELECT AVG(price) FROM products; |
COUNT() | 计数 (常用) | SELECT COUNT(order_id) FROM orders; |
MAX() | 最大值 | SELECT MAX(temperature) FROM readings; |
MIN() | 最小值 | SELECT MIN(birth_date) FROM users; |
4. 类型转换与格式化 (Casting and Formatting)
数值类型经常需要与其他类型(如字符串或日期)进行转换。
A. 显式类型转换 (Casting)
使用 :: 运算符或 CAST() 函数进行类型转换。
xxxxxxxxxx81-- 将字符串转换为整数2SELECT '123'::INTEGER; -- 结果: 12334-- 将整数转换为双精度浮点数5SELECT 10::DOUBLE PRECISION; 67-- 将浮点数截断为整数 (注意是截断,不是四舍五入)8SELECT TRUNC(123.99); -- 结果: 123B. 格式化输出
使用 TO_CHAR() 函数将数值转换为特定格式的字符串,常用于报表生成。
xxxxxxxxxx21-- 将数值格式化为货币形式 (例如: $1,234.56)2SELECT TO_CHAR(1234.56, 'FM9,999.00'); -- 结果: 1,234.565. 常用数学函数 (Common Math Functions)
PostgreSQL 内置了许多标准的数学函数:
| 函数 | 作用 | 示例 |
|---|---|---|
ROUND(x) | 四舍五入到最近的整数 | SELECT ROUND(3.5); 4 |
ROUND(x, d) | 四舍五入到 d 位小数 | SELECT ROUND(3.14159, 2); 3.14 |
CEIL(x) 或 CEILING(x) | 向上取整 | SELECT CEIL(3.1); 4 |
FLOOR(x) | 向下取整 | SELECT FLOOR(3.9); 3 |
ABS(x) | 绝对值 | SELECT ABS(-10); 10 |
SIGN(x) | 返回值的符号 (-1, 0, 1) | SELECT SIGN(-5); -1 |
MOD(a, b) | 求模(等同于 % 运算符) | SELECT MOD(10, 3); 1 |