8.5 字符串类型
| 特性 | VARCHAR(n) | CHAR(n) | TEXT |
|---|---|---|---|
| 长度限制 | 必须指定 | 必须指定 | 无需指定 |
| 存储方式 | 变长 (只存实际数据) | 定长 (用空格填充到 ) | 变长 (只存实际数据) |
| 性能 | 均衡且高效 | 低效 (因填充/截断) | 高效 (长数据使用 TOAST) |
| 推荐用途 | 姓名、邮箱、代码、ID | 极少用,除非需要定长 | 文章内容、JSON 数据、日志 |
| 存储浪费 | 无 | 浪费空间和 I/O (短字符串) | 无 |
常用操作:
除了||用来拼接字符串这个方法,其余的和MySQL里面的一样。
1. 模式匹配与比较 (Pattern Matching & Comparison)
| 运算符 / 函数 | 作用 | 示例 | 结果 |
|---|---|---|---|
|| | 连接、拼接两个字符串 | 'abc' || '123' | 'abc123' |
LIKE | 标准模式匹配 (区分大小写)。使用 % 匹配任意字符,_ 匹配单个字符。 | 'Apple' LIKE 'A%' | TRUE |
ILIKE | 不区分大小写 的模式匹配 (PostgreSQL 扩展)。 | 'apple' ILIKE 'A%' | TRUE |
2. 长度、位置与提取 (Length, Position & Substring)
| 函数 | 作用 | 示例 | 结果 |
|---|---|---|---|
LENGTH(string) | 返回字符串中的字符数(适用于 UTF-8 编码)。 | LENGTH('PostgreSQL') | 10 |
CHAR_LENGTH(string) | 别名,与 LENGTH() 相同。 | CHAR_LENGTH('中文') | 2 |
POSITION(s1 IN s2) | 查找子字符串 s1 在字符串 s2 中的起始位置 (从 1 开始)。 | POSITION('q' IN 'PostgreSQL') | 5 |
STRPOS(s2, s1) | 别名,与 POSITION 相同。 | STRPOS('PostgreSQL', 'sql') | 7 |
SUBSTRING(s, start, len) | 提取子字符串。 | SUBSTRING('PostgreSQL' FROM 5 FOR 4) | greg |
3. 清理与转换 (Cleaning & Transformation)
| 函数 | 作用 | 示例 | 结果 |
|---|---|---|---|
TRIM([BOTH/LEADING/TRAILING] chars FROM string) | 移除字符串首尾(或单侧)的指定字符(默认为空格)。 | TRIM(' hello ') | hello |
LTRIM(string, chars) | 移除左侧(Leading)的指定字符。 | LTRIM('xxxDataxxx', 'x') | Dataxxx |
RTRIM(string, chars) | 移除右侧(Trailing)的指定字符。 | RTRIM('xxxDataxxx', 'x') | xxxData |
LOWER(string) | 将所有字符转换为小写。 | LOWER('SQL') | sql |
UPPER(string) | 将所有字符转换为大写。 | UPPER('sql') | SQL |
REPLACE(s, from, to) | 替换字符串中所有出现的子字符串。 | REPLACE('a.b.c', '.', '-') | a-b-c |
4. 填充与重复 (Padding & Repeat)
| 函数 | 作用 | 示例 | 结果 |
|---|---|---|---|
LPAD(s, len, fill) | 从左侧填充 fill 字符,直到达到指定长度 len。 | LPAD('123', 5, '0') | 00123 |
RPAD(s, len, fill) | 从右侧填充 fill 字符,直到达到指定长度 len。 | RPAD('Name', 10, '-') | Name------ |
REPEAT(s, n) | 将字符串重复 次。 | REPEAT('-', 5) | ----- |
8.6 日期类型
| 类型名称 | 是否加上时区 | 存储内容 | 存储空间 | 时区处理机制 | 常用用途 |
|---|---|---|---|---|---|
| DATE | 仅存储日期 (年、月、日) | 4 字节 | 无 | 记录生日、假日、仅需日期的记录。 | |
| TIME | WITHOUT TIME ZONE | 仅存储时间 (时、分、秒) | 8 字节 | 无 | 记录商店营业时间、固定时刻表。 |
| TIMESTAMP | WITHOUT TIME ZONE | 日期 + 时间 | 8 字节 | 无转换。存储字面时间。 | 记录本地事件、无需跨时区考虑的系统时间。 |
| TIMESTAMPTZ | WITH TIME ZONE | 日期 + 时间 | 8 字节 | 存储 UTC,显示时转换为会话时区。 | 处理全球或跨时区事件、服务器日志、业务操作的最佳选择。 |
| INTERVAL | 持续时间或时间差 | 16 字节 | 无 | 计算持续时间、安排定时任务(例如:3 months 2 hours)。 |
日期+时间推荐使用timestamptz,因为加上了时区。
常用操作
A. 获取当前时间
| 函数 | 类型 | 作用 |
|---|---|---|
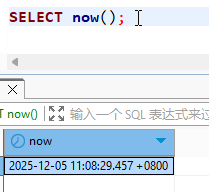
NOW() | TIMESTAMPTZ | 返回当前事务开始时的时间戳 (带时区)。 |
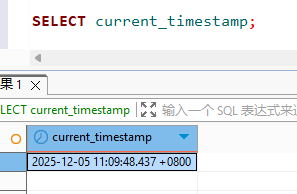
CURRENT_TIMESTAMP | TIMESTAMPTZ | 与 NOW() 相同。 |
LOCALTIMESTAMP | TIMESTAMP | 返回当前会话时区的本地时间戳 (无时区)。 |
CURRENT_DATE | DATE | 返回当前日期。 |
B. 时区设置与查询
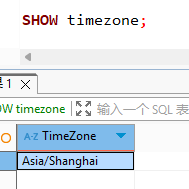
查询当前时区:SHOW timezone;
设置会话时区:SET timezone TO 'America/Los_Angeles';
C. 日期运算
1. 核心运算工具:INTERVAL (持续时间)
在 PostgreSQL 中,您不能直接用两个 DATE 或 TIMESTAMPTZ 类型进行加法,所有的日期推算都必须使用 INTERVAL 类型作为桥梁。
A. 创建 INTERVAL (持续时间)
INTERVAL 可以用多种方式表示:
| 表达式 | 含义 |
|---|---|
INTERVAL '1 day' | 一天的持续时间 |
INTERVAL '5 hours 30 minutes' | 5 小时 30 分钟 |
INTERVAL '1 year' | 一年的持续时间 |
INTERVAL '3 weeks -2 hours' | 三周减去两小时 |
B. 日期/时间推算 (加减 INTERVAL)
将 TIMESTAMP 或 DATE 类型与 INTERVAL 相加或相减,可以推算出新的日期或时间点。
| 运算符 | 操作数 | 结果类型 | 作用 |
|---|---|---|---|
+ | TIMESTAMPTZ + INTERVAL | TIMESTAMPTZ | 推算未来的一个时间点 |
- | TIMESTAMPTZ - INTERVAL | TIMESTAMPTZ | 推算过去的一个时间点 |
+ | DATE + INTEGER | DATE | 日期加天数(等同于加 INTERVAL 'n days') |
示例:
xxxxxxxxxx101-- 1. 当前时间推后 1 小时 30 分钟2SELECT NOW() + INTERVAL '1 hour 30 minutes'; 3-- 结果: (当前时间 + 1.5小时)45-- 2. 明天的日期6SELECT CURRENT_DATE + 1; 7-- 结果: (明天日期)89-- 3. 一个月前的日期 (自动处理跨月)10SELECT CURRENT_DATE - INTERVAL '1 month';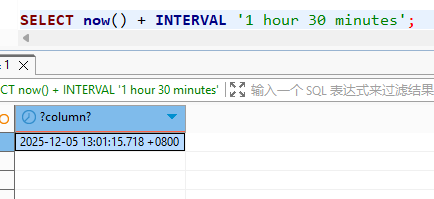
2. 计算时间差 (减法运算)
减法运算的结果取决于操作数的类型。
| 运算符 | 操作数 | 结果类型 | 作用 |
|---|---|---|---|
- | TIMESTAMPTZ - TIMESTAMPTZ | INTERVAL | 两个时间点之间的精确持续时间。 |
- | DATE - DATE | INTEGER | 两个日期之间的天数。 |
示例:
xxxxxxxxxx91-- 1. 两个日期之间相差多少天2SELECT DATE '2025-12-31' - DATE '2025-12-01'; 3-- 结果: 30 (天)45-- 2. 两个时间戳之间相差的精确持续时间6SELECT 7 (TIMESTAMPTZ '2025-12-04 10:00:00 UTC') - 8 (TIMESTAMPTZ '2025-12-04 08:30:00 UTC');9-- 结果: 01:30:00 (1小时30分钟的 INTERVAL)3. 常用日期函数
除了运算符外,还有一些常用的函数可以进行日期运算和调整:
A. EXTRACT() (提取)
用于从日期/时间类型中提取特定的组成部分(年、月、日、时、分、秒等)。
xxxxxxxxxx91-- 提取当前年份2SELECT EXTRACT(YEAR FROM NOW()); 3-- 结果: 202545-- 提取当前是星期几 (0=星期天, 6=星期六)6SELECT EXTRACT(DOW FROM NOW()); 78-- 提取日期是当年的第几天9SELECT EXTRACT(DOY FROM CURRENT_DATE);B. DATE_TRUNC() (截断)
用于将日期或时间戳截断到指定的精度(例如,截断到“月”或“小时”)。这在分组统计时非常有用。
xxxxxxxxxx61-- 截断到当月的开始日期2SELECT DATE_TRUNC('month', NOW()); 3-- 结果: 2025-12-01 00:00:00.000 (当前月的第一天 00:00:00)45-- 截断到当年6SELECT DATE_TRUNC('year', NOW());C. AGE() (计算年龄/时间差)
AGE() 函数用于计算两个时间戳之间的间隔,通常用于计算“年龄”或经过的时间。
xxxxxxxxxx31-- 假设 today 是 2025-12-042SELECT AGE(DATE '2025-12-04', DATE '2000-01-01');3-- 结果: 25 years 11 months 3 days (持续时间)4. 重点注意事项:月份加减
当您对日期进行月份加减时,PostgreSQL 会智能地处理日期:
xxxxxxxxxx41-- 假设当前是 2025-01-31 (1月31日)2-- 目标:加 1 个月3SELECT DATE '2025-01-31' + INTERVAL '1 month';4-- 结果: 2025-02-28 (因为 2 月没有 31 日,PostgreSQL 自动调整到当月的最后一天)这种行为是日期计算中特有的“智能”调整,以确保结果日期是有效的。
8.7 枚举类型
枚举类型是一种特殊的数据类型,它的值被限制在一组预定义的、有序的字符串文字列表中。
枚举类型的创建与使用
创建和使用 ENUM 分为两步:先定义类型,后使用类型。
A. 步骤 1: 创建 ENUM 类型
使用 CREATE TYPE 语句定义枚举类型及其允许的值列表。
xxxxxxxxxx81-- 创建一个名为 "order_status" 的枚举类型2CREATE TYPE order_status AS ENUM (3 'new', -- 订单刚创建4 'processing', -- 正在处理中5 'shipped', -- 已发货6 'delivered', -- 已送达7 'cancelled' -- 已取消8);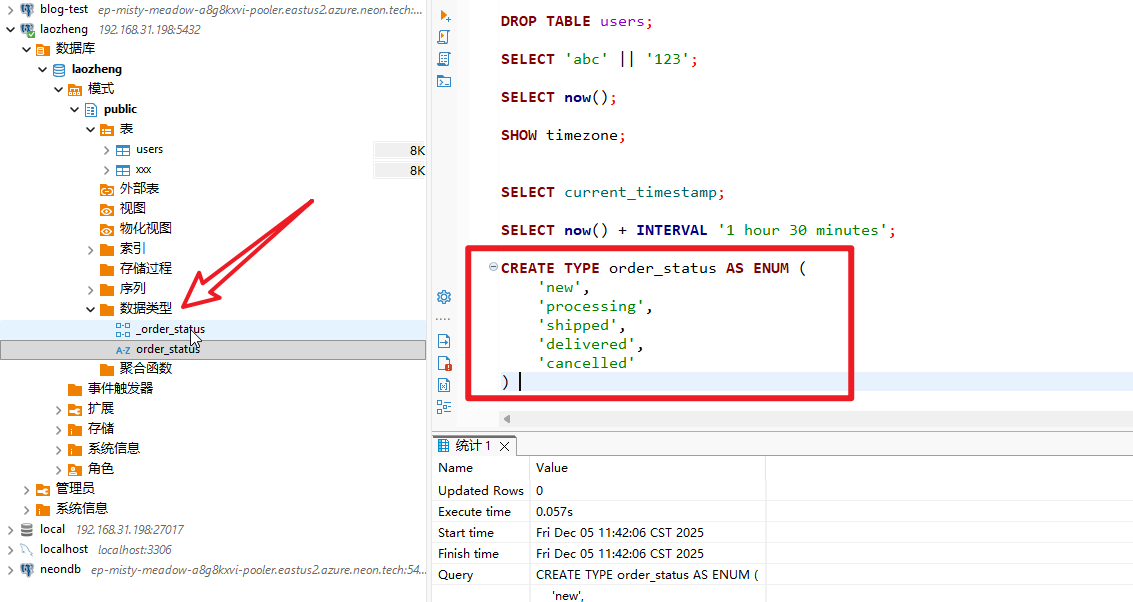
枚举类型 (ENUM) 属于特定的 SCHEMA (模式)。它们是 Schema 级别的对象,而不是整个数据库级别的对象。
B. 步骤 2: 在表中应用 ENUM 类型
在 CREATE TABLE 或 ALTER TABLE 语句中,像使用 INTEGER 或 VARCHAR 一样使用这个自定义类型。
xxxxxxxxxx61CREATE TABLE orders (2 order_id SERIAL PRIMARY KEY,3 customer_id INTEGER,4 status order_status NOT NULL DEFAULT 'new', -- 使用我们定义的枚举类型5 order_date TIMESTAMPTZ6);C. 步骤 3: 插入和查询数据
插入数据时,只能使用预定义的值。
xxxxxxxxxx101-- 成功的插入2INSERT INTO orders (customer_id, status) 3VALUES (101, 'shipped');45-- 失败的插入 (数据库会报错,因为 'complete' 不是有效值)6INSERT INTO orders (customer_id, status) 7VALUES (102, 'complete'); 89-- 查询:直接使用字符串进行过滤10SELECT * FROM orders WHERE status = 'processing';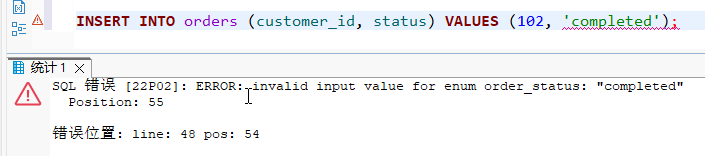
8.8 IP类型
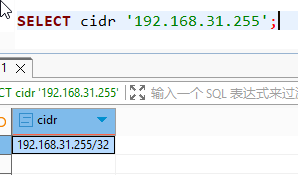
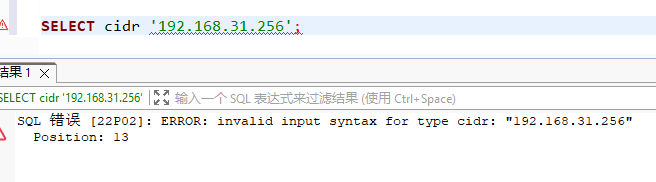
IP 地址类型是 PostgreSQL 中专门用于存储 IPv4 和 IPv6 网络地址的类型。使用这些原生类型(主要是 INET 和 CIDR)比使用普通的字符串 (VARCHAR) 具有巨大的优势,好处就是可以在存储IP时帮助做校验,其次也可以针对IP做范围查找。
比如说校验,192.168.31.255可以正常查询出来,但是192.168.31.256就会报错,因为256超过了。
比如说IP范围查找:
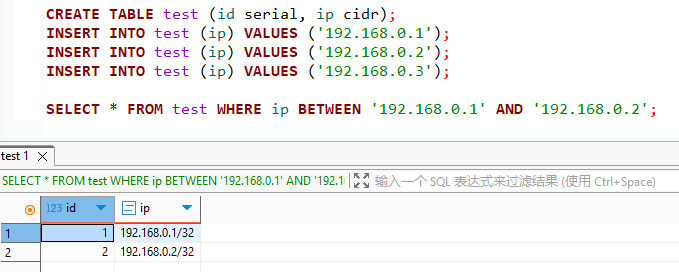
上面演示了使用between and来查找,其实IP还有很多查找方法,到时候搜索即可。
8.9 JSON 和 JSONB 类型
PostgreSQL 提供了两种原生 JSON 类型:JSON 和 JSONB,它们极大地增强了数据库处理半结构化数据的能力。
JSON 与 JSONB:核心区别
PostgreSQL 提供两种类型来存储 JSON 数据,它们最大的区别在于存储方式和查询性能。
| 特性 | JSON | JSONB (Binary JSON) |
|---|---|---|
| 存储方式 | 原始文本存储 (TEXT) | 二进制存储 (Disassembled Binary) |
| 键值顺序 | 保留。保持输入时的原始顺序和空格。 | 不保留。键值会被排序。 |
| 处理效率 | 较慢。每次查询时都需要重新解析完整的 JSON 字符串。 | 更快。 预先解析并存储在二进制结构中,可直接进行操作。 |
| 索引支持 | 仅支持有限的索引。 | 支持强大的 GIN/GiST 索引。 |
| 数据校验 | 插入时校验格式是否有效。 | 插入时校验格式是否有效,并检查键名重复。 |
| 适用场景 | 仅当您需要严格保留原始输入格式(例如,历史记录或日志)时使用。 | 所有需要查询、索引、操作 JSON 数据的场景(强烈推荐)。 |
⭐ 经验法则: 在 99% 的情况下,您应该使用
JSONB。
为什么要使用JSON JSONB这种类型?
它涉及了关系型数据库(如 PostgreSQL)与非关系型数据库(NoSQL)设计哲学之间的权衡。
使用 JSONB 来存储可变属性有其特殊的价值和优势。
核心理由在于:模式灵活性 (Schema Flexibility) 和稀疏数据 (Sparse Data) 的处理。
1. 应对模式变化和多样性 (Schema Variability)
场景: 想象一个电商平台。
| 商品类型 | 必需属性 (传统列) | 可变/特殊属性 (JSONB) |
|---|---|---|
| T恤 | name, price | material, neck_style, sleeve_length |
| 笔记本电脑 | name, price | CPU, RAM, SSD_size, screen_resolution |
| 鞋子 | name, price | sole_type, closure_type, waterproof_rating |
如果将所有这些特殊属性都创建为单独的列,您的 products 表将变得:
- 巨大:可能包含上百个列。
- 稀疏:对于一双鞋子、T恤来说,笔记本电脑的相关字段,比如
CPU、RAM等的值将永远是NULL。
使用 JSONB 的优势: 无论商品有多少种独特属性,它们都可以整齐地存储在 JSONB 字段中,避免了大量的 NULL 值。
2. 加快迭代和敏捷开发 (Agility)
- 传统方式: 如果需要为笔记本电脑添加一个新的属性
has_thunderbolt,您必须执行ALTER TABLE ADD COLUMN has_thunderbolt BOOLEAN;。这需要数据库停机或长时间的锁表操作。 - JSONB 方式: 您可以直接在应用程序中开始存储
{..., "has_thunderbolt": true}。无需更改数据库结构。这极大地加快了新功能或新产品线的上线速度。
3. 应用层映射简洁 (Application Mapping)
现代应用程序(如 JavaScript, Python, Java)通常天然地以对象、字典或 Map 的形式处理数据。
- 将
JSONB直接加载到应用程序的对象中,映射非常简单。 - 无需将几十个稀疏的
NULL字段映射到应用层对象。
4. 数据局部性与 I/O 效率 (Data Locality)
当您查询一个商品的所有属性时,传统方式可能需要从多张属性表中 JOIN 数据。
使用 JSONB 时,商品的所有属性都存储在同一行、同一个数据块中。这使得 PostgreSQL 可以一次性读取所有相关数据,减少了磁盘 I/O,提高了查询效率。
结论:最佳实践是“混合存储”
最好的数据库设计,往往是混合存储 (Hybrid Approach):
| 存储方式 | 适用字段类型 | 目的和优势 |
|---|---|---|
| 独立列 (Traditional) | product_id, name, price, stock, is_active | 满足严格关系约束 (PRIMARY KEY, NOT NULL, FOREIGN KEY);需要高频过滤;需要严格的数据类型校验。 |
| JSONB 列 (Flexible) | specs, accessories, custom_fields | 存储可变、稀疏、非结构化的数据。需要快速迭代和模式灵活性。 |
JSON 和 JSONB 存储的值
PostgreSQL 的 JSON 和 JSONB 列可以存储任何有效的顶层 JSON 结构,包括:
对象 (Object):
{ "key": "value", ... }(最常见)数组 (Array):
[ "value1", "value2", ... ]标量值 (Scalar Value):
- 字符串 (String):
"hello world" - 数字 (Number):
12345或3.14 - 布尔值 (Boolean):
true或false - 空值 (Null):
null
- 字符串 (String):
虽然可以存储这么多种值,但是一般来说都是存储对象。
JSONB操作
创建表
xxxxxxxxxx71-- DDL: 创建表2CREATE TABLE products (3 product_id SERIAL PRIMARY KEY,4 name VARCHAR(100) NOT NULL,5 -- 核心 JSONB 列6 attributes JSONB 7);插入数据
xxxxxxxxxx131INSERT INTO products (name, attributes) VALUES 2(3 'Running Shoes X1', 4 '{"color": "Black", "stock": 150, "tags": ["outdoor", "waterproof"], "specs": {"material": "mesh", "weight": 0.3}, "is_clearance": false}'5),6(7 'Premium T-Shirt', 8 '{"color": "White", "stock": 300, "tags": ["cotton", "basic"], "size": "L", "is_clearance": false}'9),10(11 'Smart Watch V2', 12 '{"color": "Silver", "stock": 50, "tags": ["electronics", "waterproof"], "specs": {"material": "aluminum", "display": "OLED"}, "is_clearance": true}'13);查询操作 (Querying - DQL)
A. 提取值 (Accessing Values: -> 和 ->>)
| 查询目标 | SQL 语句 | 结果 |
|---|---|---|
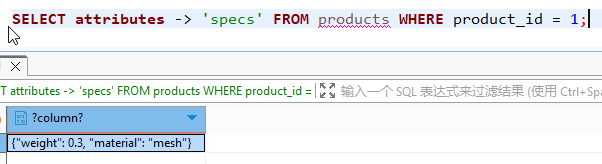
| 提取 JSON 键值 (保留 JSONB 类型) | SELECT attributes -> 'specs' FROM products WHERE product_id = 1; | {"material": "mesh", "weight": 0.3} |
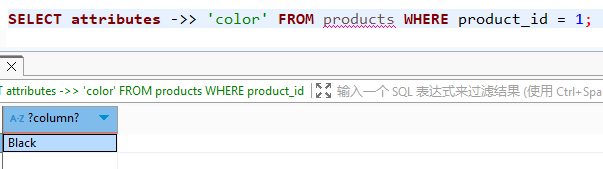
| 提取 TEXT 键值 (返回字符串) | SELECT attributes ->> 'color' FROM products WHERE product_id = 1; | Black |
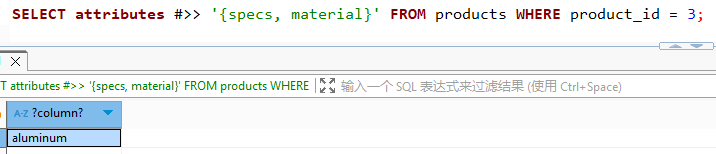
| 提取嵌套值 (按路径) | SELECT attributes #>> '{specs, material}' FROM products WHERE product_id = 3; | aluminum |
B. 过滤:基于存在性 (?, ?&)
| 查询目标 | SQL 语句 | 解释 |
|---|---|---|
查找所有有 size 属性的商品 | SELECT name FROM products WHERE attributes ? 'size'; | T-Shirt (产品 2) |
查找同时具有 specs 和 tags 属性的商品 | SELECT name FROM products WHERE attributes ?& ARRAY['specs', 'tags']; | Shoes, Watch (产品 1, 3) |
C. 过滤:基于包含性 (@>)
这是最强大的过滤方式,用于检查 JSONB 是否包含一个更小的 JSON 结构。
xxxxxxxxxx51-- 查找所有包含 "tags" 为 "waterproof" 的商品2SELECT name 3FROM products 4WHERE attributes @> '{"tags": ["waterproof"]}';5-- 结果: Running Shoes X1, Smart Watch V2xxxxxxxxxx51-- 查找所有库存大于 100 且颜色为 White 的商品2SELECT name 3FROM products 4WHERE attributes @> '{"stock": 300, "color": "White"}';5-- 结果: Premium T-Shirt4. 数据更新与修改 (Modification - DML)
PostgreSQL 使用 || 进行合并(Merge),使用 - 进行删除。
A. 合并/新增属性 (||)
|| 运算符将右侧的 JSON 合并到左侧的 JSON 中。如果键已存在,新值会覆盖旧值。
xxxxxxxxxx61-- 目标:为 Shoes (ID 1) 添加一个新的 'origin' 属性,并更新 'stock'2UPDATE products 3SET attributes = attributes || '{"origin": "China", "stock": 140}'4WHERE product_id = 1;56-- 结果: attributes 中会多出 "origin":"China","stock" 值变为 140。B. 删除属性 (-)
使用 - 运算符从 JSON 对象中删除一个或多个顶级键。
xxxxxxxxxx41-- 目标:从 T-Shirt (ID 2) 中删除 'size' 属性2UPDATE products 3SET attributes = attributes - 'size'4WHERE product_id = 2;5. 性能优化:索引 (Indexing)
对于频繁执行的 JSONB 查询,必须创建 GIN 索引以提高性能。
A. 全文索引 (针对整个 JSONB 对象)
用于优化 ?, @> 等操作符的查询。
xxxxxxxxxx21-- 创建 GIN 索引,优化对 keys/values 的查找2CREATE INDEX idx_products_attributes_gin ON products USING GIN (attributes);B. 表达式索引 (针对特定路径的值)
用于优化频繁过滤特定嵌套键的查询。
xxxxxxxxxx31-- 创建一个索引,专门针对 attributes 中 color 键的值2-- 目的: 快速查找所有 color = 'Black' 的商品3CREATE INDEX idx_products_color ON products ((attributes ->> 'color'));通过这套完整的操作,您可以看到 JSONB 如何优雅地处理半结构化数据,同时通过原生操作符和索引保持了强大的查询性能和数据完整性。
8.10 复合类型
复合类型(Composite Type),也称为行类型 (Row Type),是 PostgreSQL 中一个非常强大的特性,它允许您将多个字段(或列)组合成一个单一的数据类型。
这在概念上类似于编程语言中的结构体 (struct) 或对象 (Object)。复合类型在数据库设计中常用于提高数据组织的逻辑性、简化函数签名,以及增强代码的可读性。
1. 复合类型的定义和用途
A. 定义 (Definition)
复合类型是一个用户定义的、包含有序字段列表的数据结构。每个字段都有自己的名称和数据类型。
B. 核心用途
- 作为表列类型: 将逻辑相关的多个属性打包为一个列,而不是在主表中创建多个分散的列。
- 作为函数返回值: 允许 SQL 或 PL/pgSQL 函数返回一个包含多个值的结构化结果,而不是仅仅返回一个值。
- 代码组织: 提高查询和函数定义的清晰度。
2. 复合类型的创建和使用示例
我们以创建一个用于表示“地址”的复合类型为例:
步骤 1: 创建复合类型
xxxxxxxxxx71-- 创建一个名为 'address_type' 的复合类型2CREATE TYPE address_type AS (3 street VARCHAR(100),4 city VARCHAR(50),5 zip_code VARCHAR(10),6 country VARCHAR(50)7);
步骤 2: 在表中使用复合类型
现在,我们可以在其他表中使用这个新类型,将其作为一个列的数据类型。
xxxxxxxxxx61CREATE TABLE companies (2 company_id SERIAL PRIMARY KEY,3 name VARCHAR(100),4 -- 使用复合类型 address_type 作为列类型5 headquarters address_type 6);步骤 3: 插入和访问数据
插入数据
插入复合类型的值时,需要使用 行构造器 (Row Constructor) 语法,用圆括号 () 括起来,字段之间用逗号 , 分隔。
xxxxxxxxxx121INSERT INTO companies (name, headquarters)2VALUES (3 'TechCorp Global', 4 ROW('123 Main St', 'San Francisco', '94107', 'USA') -- 使用 ROW 关键字5);67-- 也可以省略 ROW 关键字(但在复杂场景中推荐使用 ROW)8INSERT INTO companies (name, headquarters)9VALUES (10 'Innovate Ltd', 11 ('456 Oak Ave', 'London', 'SW1A 0AA', 'UK') 12);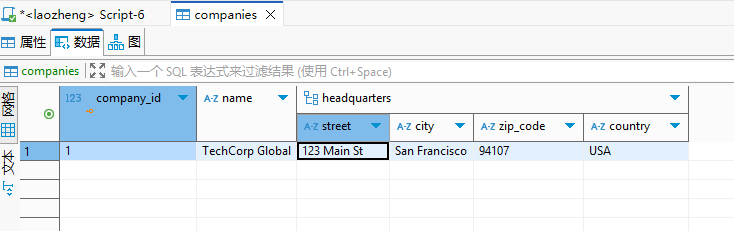
访问数据(点运算符)
要访问复合类型列中的单个字段,需要使用点运算符(.),并用括号 () 将复合类型列括起来。
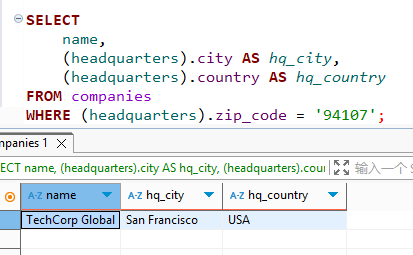
xxxxxxxxxx71-- 查询:提取所有公司的城市字段2SELECT 3 name, 4 (headquarters).city AS hq_city,5 (headquarters).country AS hq_country6FROM companies7WHERE (headquarters).zip_code = '94107'; 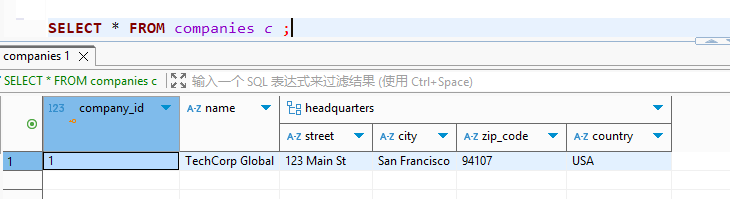
3. 复合类型的特殊用法
A. 作为函数的返回类型
复合类型在自定义函数中非常强大,允许函数返回结构化数据。
xxxxxxxxxx131-- 创建一个返回 address_type 的函数2CREATE OR REPLACE FUNCTION get_london_hq()3RETURNS address_type AS $$4SELECT 5 '456 Oak Ave'::VARCHAR, 6 'London'::VARCHAR, 7 'SW1A 0AA'::VARCHAR, 8 'UK'::VARCHAR;9$$ LANGUAGE SQL;1011-- 调用函数12SELECT * FROM get_london_hq();13-- 结果: 返回一个包含 street, city, zip_code, country 四个字段的行。B. 表的隐式复合类型 (ROW)
PostgreSQL 中的每张表都会自动定义一个与其行结构相同的复合类型。
- 例如,您创建了
CREATE TABLE users (id INT, name VARCHAR)。 - 系统自动创建了一个隐式的行类型,您可以称之为
users。 - 这允许您在函数中直接使用表名作为返回类型:
RETURNS SETOF users(返回多行 users 表的结构)。
4. 总结:复合类型的优点
- 逻辑分组: 将逻辑上相关的字段(如地址的各个部分)绑定在一起,提高数据模型清晰度。
- 数据简化: 减少表中的列数,使 DDL(数据定义语言)更简洁。
- 函数效率: 允许函数以单行返回多个值,比返回多个单独的参数更优雅和高效。
对性能的影响
对性能是有一点影响,但是按照下面来操作,性能影响可以忽略。记住一点即可:高频过滤/索引就不要加到复合类型里面。
| 场景 | 建议 | 理由 |
|---|---|---|
| 高频过滤/索引 | 避免使用复合类型。 | 索引和查询速度至关重要,应使用原生列。 |
| 数据逻辑分组 | 可以使用复合类型。 | 提高数据模型的可读性和代码组织性,性能损失可接受。 |
| 函数返回结构 | 强烈推荐使用。 | 这是复合类型最强大的应用场景,极大地简化了函数接口。 |
| 访问频率低 | 可以使用复合类型。 | 如果该字段很少被查询或过滤,访问开销可以忽略。 |
不要因为性能而避免使用复合类型,因为其性能损失通常很小。只有当您确定需要对复合类型内部的某个字段进行高频、高性能的索引和过滤时,才应将其拆分为原生列。
8.11 数组类型
数组类型(Array Type)是 PostgreSQL 中一个非常实用和强大的特性,它允许您在一个表的列中存储同一种数据类型的多个值。
数组类型是 PostgreSQL 的原生特性,可以用于任何基本数据类型(如 INTEGER[]、VARCHAR[]、TIMESTAMPTZ[],甚至是自定义类型)。
1. 数组的定义与声明
A. 定义 (Definition)
数组是一个有序的、同质(Homogeneous,即所有元素类型相同)的值集合。PostgreSQL 数组可以是一维、二维甚至多维的。
B. 声明语法
有两种主要的方式来声明数组列:
使用方括号 (最常用):
xxxxxxxxxx51CREATE TABLE users (2user_id SERIAL PRIMARY KEY,3tags VARCHAR(50)[], -- 存储字符串数组 (例如:'admin', 'editor')4access_levels INTEGER[] -- 存储整数数组 (例如:10, 20, 30)5);使用
ARRAYSQL关键字:xxxxxxxxxx41CREATE TABLE products (2product_id SERIAL PRIMARY KEY,3weekly_sales INTEGER ARRAY -- 存储整数数组4);
2. 数组的数据操作
A. 插入和赋值
插入数组数据时,使用 ARRAY[...] 构造器或花括号 {...}:
xxxxxxxxxx71-- 示例 1: 使用花括号语法2INSERT INTO users (tags, access_levels) 3VALUES ('{premium, beta}', '{10, 50}'); 45-- 示例 2: 使用 ARRAY 构造器6INSERT INTO users (tags, access_levels) 7VALUES (ARRAY['guest', 'basic'], ARRAY[10]); 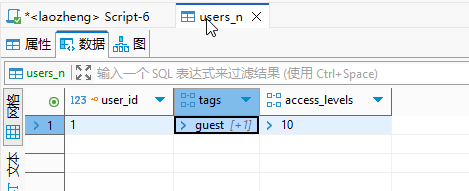
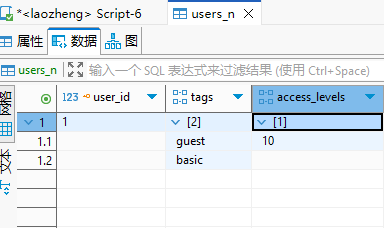
B. 访问单个元素 (Subscripts)
PostgreSQL 数组的索引默认从 1 开始,而不是像许多编程语言那样从 0 开始。
xxxxxxxxxx101-- 查询: 获取用户 ID 1 的第一个 tag2SELECT tags[1] 3FROM users 4WHERE user_id = 1;5-- 结果: 'premium'67-- 更新: 修改用户 ID 1 的第二个 access_level8UPDATE users 9SET access_levels[2] = 60 10WHERE user_id = 1; C. 访问数组切片 (Slicing)
您可以提取数组的一部分作为子数组:
xxxxxxxxxx51-- 查询: 获取 access_levels 数组的第 2 到第 3 个元素2SELECT access_levels[2:3] 3FROM users 4WHERE user_id = 1; 5-- 结果: {60, 50}3. 数组的核心操作符 (Operators)
数组的强大之处在于其专门用于集合操作的操作符。
| 操作符 | 含义 | 示例 | 作用 |
|---|---|---|---|
&& | 重叠 (Overlap) | tags && '{admin}' | 检查两个数组是否至少有一个共同元素。 |
@> | 包含 (Contains) | tags @> '{basic}' | 检查左侧数组是否包含右侧数组的所有元素。 |
<@ | 被包含于 (Contained By) | '{basic}' <@ tags | 检查左侧数组是否是右侧数组的子集。 |
示例 SQL:
xxxxxxxxxx91-- 查找至少有一个 'admin' 或 'beta' 标签的用户2SELECT user_id 3FROM users 4WHERE tags && ARRAY['admin', 'beta'];56-- 查找所有包含 'basic' 标签的用户 (使用包含操作符)7SELECT user_id 8FROM users 9WHERE tags @> ARRAY['basic'];4. 关键函数:unnest (展开)
unnest() 函数是处理数组时最常用的函数之一。它将数组中的每一个元素展开成一行。这对于连接 (JOIN) 或进行分组统计非常重要。
xxxxxxxxxx91-- 示例:将 tags 数组中的所有元素展开成单独的行2SELECT 3 user_id, 4 unnest(tags) AS individual_tag5FROM users;67-- 结果 (User 1 的数据):8-- 1 | premium9-- 1 | beta5. 性能与索引
对于数组的查询(尤其是使用 &&, @>, <@ 操作符),PostgreSQL 提供了专用的 GIN 索引 (Generalized Inverted Index) 来保证高性能:
xxxxxxxxxx21-- 提升数组搜索和重叠查询的性能2CREATE INDEX idx_user_tags ON users USING GIN (tags); 6. 与 JSONB 的区别
| 特性 | 数组 (ARRAY) | JSONB (数组或对象) |
|---|---|---|
| 数据类型 | 同质 (所有元素必须类型相同) | 异质 (可以混合存储数字、字符串、布尔值) |
| 结构 | 仅列表 (List) | 对象、数组、标量皆可 |
| 用途 | 存储标签、权限列表、有序简单值集合。 | 存储复杂的、可变的、半结构化数据。 |
简单总结: 如果您只需要一个简单的、同类型的列表,使用 数组类型;如果您需要存储复杂、异构或有命名键值对的数据,请使用 JSONB。
8.12 其它类型
postgresql还有很多其它类型,但是就不介绍了,用的时候查询即可。
| 类别 (Category) | 类型 (Type) | 常用度 (Frequency) | 描述 (Description) |
|---|---|---|---|
| 二进制/大对象 | BYTEA | 低 | 用于存储原始的二进制字符串,例如图片、加密数据、文件内容等。 |
| 全局标识符 | UUID | 高 | 128 位全局唯一标识符。在分布式数据库或微服务架构中,BIGSERIAL 无法保证全局唯一性,此时 UUID 是首选的主键类型。 |
| 范围类型 | INT4RANGE / DATERANGE 等 | 中 | 存储一个连续的范围,例如整数范围、日期范围、时间戳范围等,常用于排程和预约系统。 |
| 全文搜索 | TSVECTOR | 中 | 经过预处理的文档数据,用于全文搜索。 |
| TSQUERY | 中 | 经过查询预处理后的查询条件,用于与 TSVECTOR 匹配。 | |
| 空间/地理 | POINT | 低 | 存储二维平面上的坐标点。 |
| POLYGON | 低 | 存储二维平面上的多边形区域。 | |
| 货币 | MONEY | 低 | 存储货币金额。由于其行为依赖于 locale,通常推荐使用 NUMERIC 或 BIGINT 来存储精确的货币数据。 |
| XML 数据 | XML | 低 | 存储 XML 文档。支持 XPath 查询。 |
| 特殊类型 | OID | 低 | 对象标识符,PostgreSQL 内部使用(例如,用于大对象存储)。 |
9.表
表的构建语句,基本和MySQL一致。核心在于构建表的时候,要加上一些约束。
9.1 约束
9.1.1 主键
作用: 唯一地标识表中的每一行。
特性: 主键是以下两个约束的组合:
NOT NULL:主键列的值不能为 NULL。UNIQUE:主键列的值在表中必须是唯一的。
创建示例:
xxxxxxxxxx41CREATE TABLE users (2 user_id SERIAL PRIMARY KEY,3 ...4);9.1.2 非空
作用: 强制指定列必须包含值,不允许存储 NULL。
创建示例:
xxxxxxxxxx51CREATE TABLE products (2 name VARCHAR(100) NOT NULL,3 price NUMERIC NOT NULL,4 ...5);9.1.3 唯一
作用: 保证指定列或列组合中的值在表中是唯一的,但允许 NULL 值(与主键不同,可以有多个 NULL)。
创建示例 (列级):
xxxxxxxxxx41CREATE TABLE users (2 username VARCHAR(50) UNIQUE,3 ...4);创建示例 (表级/复合唯一键):
xxxxxxxxxx61-- 保证 name 和 department 组合是唯一的2CREATE TABLE employees (3 name VARCHAR(100),4 department VARCHAR(50),5 UNIQUE (name, department)6);9.1.4 检查
作用: 允许您定义一个自定义的布尔表达式,强制所有插入或更新的值都必须满足该条件。
创建示例:
xxxxxxxxxx51CREATE TABLE products (2 price NUMERIC CHECK (price > 0), -- 价格必须大于零3 stock_level INTEGER CHECK (stock_level >= 0 AND stock_level <= 1000),4 ...5);9.1.5 外键(不推荐使用)
FOREIGN KEY (外键)
作用: 保证一列或多列(子表/参照表)的值必须匹配另一张表(父表/被参照表)中某一行主键或唯一键的值。
创建示例:
xxxxxxxxxx51CREATE TABLE orders (2order_id SERIAL PRIMARY KEY,3user_id INTEGER REFERENCES users (user_id), -- 列级定义4order_date DATE5);
这只是说对于大规模、高性能、高并发的项目,或者当你在使用分布式数据库时,外键可能不适合。这些应用通常需要高吞吐量的读写操作,外键会影响数据库的性能,尤其在数据量大且访问频繁的情况下。写操作时,数据库会检查外键约束,这会成为性能瓶颈。
但是如果你做小项目,还是可以使用的,毕竟变更不是那么频繁。
没有外键之后,表之间的关联怎么处理呢?
数据完整性检查的逻辑被写入到后端应用程序的代码中(例如 Java, Python, Node.js 的服务层)。
- 实现方式: 在执行数据操作(如插入订单前)时,应用代码会先执行一次查询,验证引用的主键(如
CustomerID)是否存在。 - 优点: 提供了极大的灵活性,避免了数据库锁和性能瓶颈,并且更容易适应分布式架构和分库分表。
- 缺点: 增加了应用代码的复杂性,并且需要确保所有修改数据的入口都执行了相同的验证逻辑,否则可能出现数据不一致。
9.1.6 默认值
作用: 如果 INSERT 语句没有为该列提供值,系统将自动使用默认值。
创建示例:
xxxxxxxxxx51CREATE TABLE tasks (2 task_id SERIAL PRIMARY KEY,3 status VARCHAR(20) NOT NULL DEFAULT 'pending', -- 默认状态为 'pending'4 created_at TIMESTAMPTZ DEFAULT NOW() -- 默认值为当前时间5);9.2 触发器
这个内容我大胆的说一声,不用学习,因为现在架构原则是“瘦数据库,胖服务”,将业务逻辑集中在应用层,而让 PostgreSQL 专注于其最擅长的工作:高效且可靠地存储数据。这是目前公认的最佳实践。并且像prisma这样的ORM中不能写触发器,需要在原始SQL迁移里面写,所以更加不用管了。
1. 触发器的主要缺点
触发器的问题大多围绕着隐藏性和可维护性展开。
A. 隐藏的逻辑 (Hidden Logic)
触发器是隐式运行的。当开发者看到一个简单的 INSERT 语句时,他们预期数据会立即进入表中。如果这个 INSERT 语句触发了一个复杂的函数,导致数据被修改、插入到其他表中,甚至抛出错误,但逻辑代码却在数据库层面,应用程序代码中完全看不到。
- 后果: 难以调试、难以维护、难以理解系统行为。
B. 性能开销 (Performance Overhead)
触发器本质上是在同步执行代码。对于任何批量操作(例如一次性导入 10 万条记录),如果触发器是 FOR EACH ROW(行级触发),那么您的代码就会被执行 10 万次。
- 后果: 大大降低了批量操作的性能。触发器的代码必须非常高效,否则会拖垮数据库写入速度。
C. 测试和部署复杂性 (Testing Difficulty)
应用程序层的代码(如 Java, Python, Go)可以使用单元测试和集成测试框架进行隔离测试。但触发器逻辑是与数据库紧密绑定的。
- 后果: 要测试一个触发器,您必须执行真实的 DML 语句,并在测试中验证数据库状态,使得测试过程更加复杂和缓慢。
2. 现代架构的首选替代方案
在许多项目中,触发器的功能已经被其他架构组件所取代:
| 触发器功能 | 替代方案 | 理由 |
|---|---|---|
| 数据校验 | 原生约束 (CHECK, NOT NULL) | 最优解。约束是数据库中最快、最可靠的校验方式,性能远高于触发器。 |
| 填充默认值 | DEFAULT 关键字 | 最优解。在列定义中直接设置默认值,比触发器更简洁。 |
| 级联操作 | 外键级联 (ON DELETE CASCADE) | 最优解。使用外键定义级联删除/更新,由数据库底层高效处理。 |
| 审计/日志记录 | 应用层服务/CDC | 将审计逻辑放在应用服务中,或使用 Change Data Capture (CDC) 工具异步处理,避免同步写入开销。 |
| 复杂业务逻辑 | 应用服务层 (Service Layer) | 业务逻辑应放在应用代码中,便于调试、测试和扩展。 |
3. 结论:触发器何时仍然有用?
尽管被广泛替代,触发器仍然是某些特定场景的最佳工具:
- 强制性数据完整性: 当业务规则必须在任何访问数据库的应用程序(包括 CLI 工具、旧系统、第三方 BI 工具)上得到保证时。
- 复杂的跨行校验: 当需要根据表中其他行的状态来决定当前行是否有效时,只有触发器或存储过程能实现。
- 兼容性: 维护遗留系统,或与大量依赖数据库逻辑的系统集成。
9.3 表空间
这个也不用管,知道即可。
表空间(Tablespace)是 PostgreSQL 中一个非常重要的管理特性,它允许数据库管理员(DBA)控制数据库对象(如表、索引)在文件系统上的物理存储位置。如果没有指定tablespace,PGSQL会自动指定一个位置作为默认的存储位置。
简单来说,表空间就是将数据库中的一个逻辑名称映射到服务器文件系统上的一个物理目录。
表空间的核心作用
表空间的核心价值在于将数据库的存储与文件系统的物理设备分离开,从而实现存储优化和管理。
A. 性能优化:I/O 平衡 (I/O Distribution)
这是使用表空间的首要原因。
问题: 默认情况下,所有表和索引都存储在同一个磁盘分区上,这可能导致 I/O 瓶颈。
解决方案: 通过创建不同的表空间,可以将:
- 频繁访问的大表 放在快速的 SSD 或高性能阵列上。
- 不常访问的归档数据 放在慢速、高容量的 HDD 存储上。
- 索引 放在与表数据不同的物理磁盘上,从而分散 I/O 负载,提高并发查询性能。
B. 存储管理 (Storage Management)
- 问题: 数据库的主分区空间可能不足。
- 解决方案: 可以简单地在新的、更大的磁盘分区上创建新的表空间,并将数据迁移到新的表空间中,而无需重新配置整个服务器或数据库集群。
9.4 视图
视图的使用还是蛮简单的,只需要创建一次,这个视图就会存储在PGSQL系统中,直到你删除它。可以把它当作表来查询,对于一些敏感数据的、复杂查询逻辑的,可以先创建视图,然后查询视图。
但是在prisma里面的使用有点复杂,纯数据库操作还是很简单的。
视图(View)是 PostgreSQL 中一种数据库对象,它被认为是虚拟表 (Virtual Table)。
视图本身并不存储数据,它只是一个存储起来的 SQL 查询语句。每次查询视图时,数据库都会执行这个底层的查询,并返回结果集,但对用户来说,视图的使用方式和表是完全一样的。
图本身并不存储数据,它只是一个存储起来的 SQL 查询语句。每次查询视图时,数据库都会执行这个底层的查询,并返回结果集,但对用户来说,视图的使用方式和表是完全一样的。
1. 标准视图 (Standard Views)
A. 定义与创建
标准视图只是查询的一个别名或封装。
xxxxxxxxxx141-- 假设我们有一个 orders 表和一个 users 表23CREATE VIEW active_customer_orders AS4SELECT 5 o.order_id, 6 u.username, 7 o.order_total,8 o.order_date9FROM 10 orders o11JOIN 12 users u ON o.user_id = u.user_id13WHERE 14 u.is_active = TRUE; -- 只显示活跃客户的订单创建很简单:
创建之后,可以看到它在系统内:
一旦创建,您可以像查询普通表一样查询它:
xxxxxxxxxx21SELECT * FROM active_customer_orders WHERE order_total > 500;2-- 数据库执行的操作:运行底层的 JOIN 和 WHERE 语句
B. 视图的核心价值 (为什么要用视图?)
视图的主要价值在于提供抽象、简化和安全。
简化复杂查询 (Simplification/Abstraction): 将复杂的
JOIN、子查询和WHERE条件封装在一个视图中。开发人员不必每次都重写复杂的逻辑,只需查询视图即可。安全性/访问控制 (Security):
- 视图可以用来隐藏底层表中的敏感列。例如,您可以创建一个视图,不包含
users表中的salary或social_security_number列。 - 然后,您可以授予用户对视图的访问权限,同时拒绝他们对原始表的访问权限。
- 视图可以用来隐藏底层表中的敏感列。例如,您可以创建一个视图,不包含
逻辑数据层 (Logical Layer): 如果底层表的结构(例如,列名)发生了变化,您可以修改视图的定义来适应这些变化,而应用程序仍然查询旧的视图名。这有助于保持对旧版应用程序的兼容性。
2. 物化视图 (Materialized Views - MVs)
物化视图是 PostgreSQL 视图家族中一个功能更强大、专门用于性能优化的类型。
A. 定义与用途
- 存储数据: 与标准视图不同,物化视图不仅存储查询定义,还存储查询的结果数据(物理地存储在磁盘上)。
- 用途: 适用于那些底层数据变化不频繁,但查询计算成本很高且需要快速响应的场景。
B. 创建与数据刷新 (Refresh)
创建物化视图时,会立即执行查询并将结果存入磁盘。
xxxxxxxxxx81-- 创建一个物化视图,存储每月销售总额2CREATE MATERIALIZED VIEW monthly_sales_summary AS3SELECT 4 DATE_TRUNC('month', order_date) AS sales_month,5 SUM(order_total) AS total_revenue6FROM 7 orders8GROUP BY 1;关键点: 物化视图的数据是静态的。当底层表(orders)数据发生变化时,物化视图的数据不会自动更新,需要手动或定时刷新。
xxxxxxxxxx21-- 手动刷新物化视图:重新执行查询并更新磁盘数据2REFRESH MATERIALIZED VIEW monthly_sales_summary;注意: 刷新操作可能会是一个耗时操作,特别是对于大型视图。
3. 视图的可更新性 (Updatability)
- 标准视图: 默认情况下,如果视图是基于单表、不包含
GROUP BY、DISTINCT或复杂JOIN的简单查询,则它是可更新的。您可以通过INSERT,UPDATE,DELETE语句直接操作它。 - 复杂视图: 如果视图涉及多个表的
JOIN或聚合函数,则它通常是只读的。 - 解决方法 (INSTEAD OF Trigger): 对于复杂视图,您可以创建
INSTEAD OF触发器,告诉数据库在尝试更新视图时应该执行哪些底层的INSERT/UPDATE/DELETE操作,从而实现对复杂视图的更新。
总结来说,标准视图是提供安全和简化抽象的逻辑工具;物化视图是提升复杂查询性能的物理工具。
标准视图的执行流程
| 步骤 | 操作 | 描述 |
|---|---|---|
| 首次定义 | CREATE VIEW ... | 只需要创建一次,定义将被永久存储。会永久存储在 PostgreSQL 的系统目录中。 它作为数据库的一个对象,和表、函数一样,一旦创建就会一直存在,直到您使用 DROP VIEW 语句将其删除。 |
| 第一次查询 | SELECT * FROM view_name | 数据库执行底层查询,返回最新数据。 |
| 数据变更 | INSERT INTO orders ... | 插入新数据到视图引用的底层表。 |
| 第二次查询 | SELECT * FROM view_name | 数据库再次执行底层查询,自动包含新的数据。 |
| 修改定义 | CREATE OR REPLACE VIEW ... | 在不影响外部调用视图的代码的情况下,修改底层的查询逻辑。 |
因此,视图是您将复杂查询抽象化的理想工具,无需担心性能或数据的时效性问题(数据总是实时的)。
9.5 索引
1. 索引的定义与工作原理
A. 核心定义:查找加速器
您可以将数据库索引想象成一本书的目录(或索引页):
- 没有索引 (全表扫描): 如果您想查找书中某个特定主题(如“触发器”)的内容,您必须从第一页开始,逐页翻阅,直到找到为止。
- 有索引: 您可以直接翻到书的索引页,找到“触发器”对应的页码(例如第 456 页),然后直接跳到那一页。
在数据库中: 索引存储了特定列的值以及该值在磁盘上对应的数据行的物理位置。这样,数据库不必读取整个表,可以直接定位到所需的数据行。
B. 索引的优缺点权衡
索引是一把双刃剑,它以写入的代价换取读取的加速。
| 特性 | 优点 (Pros) | 缺点 (Cons) |
|---|---|---|
| 查询 (SELECT) | 显著加速 WHERE 子句中的过滤、JOIN 操作和 ORDER BY 排序。 | 无。 |
| 写入 (DML) | 无。 | 减慢 INSERT, UPDATE, DELETE 操作。因为每当数据发生变化时,数据库不仅要更新表数据,还要同步更新索引结构。 |
| 存储 | 无。 | 占用额外的磁盘空间。 |
2. PostgreSQL 索引的关键类型
PostgreSQL 提供了多种索引类型,每种都针对不同的查询场景进行了优化。
A. B-tree (B-树)
- 特点: PostgreSQL 的默认和最常用的索引类型。
- 适用场景: 适用于等值查询 (
=)、范围查询 (<,>,BETWEEN)、模糊匹配 (LIKE 'A%') 和排序。 - 工作原理: 保持数据排序,结构平衡,适用于大多数通用查询。
B. GIN (Generalized Inverted Index)
特点: 倒排索引,擅长处理包含多个值的列(如数组和 JSONB)。
适用场景:
- 数组/JSONB:加速
JSONB的?(键存在) 和@>(包含) 操作,以及数组的重叠 (&&) 操作。 - 全文搜索:加速
TSVECTOR字段的搜索。
- 数组/JSONB:加速
C. GiST (Generalized Search Tree)
- 特点: 通用搜索树,非常灵活,用于处理非标准数据类型和查询。
- 适用场景: 地理空间数据 (
POINT,POLYGON)、范围类型 (DATERANGE) 和复杂的全文搜索。
D. BRIN (Block Range Index)
- 特点: 块范围索引,占用空间极小,适用于数据在物理存储上自然有序的大表。
- 适用场景: 日志表、时间序列数据等,数据写入顺序通常就是查询顺序。
3. 索引的创建 (CREATE INDEX)
在创建索引时,您通常不需要指定索引类型,但仅限于您想使用 PostgreSQL 的默认类型——B-tree 时。如果您想使用任何其他特殊用途的索引类型(例如 GIN、GiST 或 BRIN),则必须明确指定。
创建索引的基本语法非常简单:
xxxxxxxxxx81-- 语法格式2CREATE INDEX [索引名称] ON [表名] USING [索引类型名] ([列名]) ;34-- 示例:为 users 表的 email 字段创建索引,以加速登录查询5CREATE INDEX idx_users_email ON users (email);67-- 明确指定 GIN 8CREATE INDEX idx_users_name ON users USING GIN (name);4. 最佳实践:何时创建索引?
- 高基数 (High Cardinality) 的列: 唯一值数量多的列(如
email、user_id)。索引在区分度高的列上最有效。 - 频繁用于
WHERE或JOIN的列: 索引应放在查询条件中经常出现的字段上。 - 外键 (Foreign Keys): 应该在外键列上创建索引,以加速
JOIN操作和确保引用的完整性。 - 避免索引低基数列: 不要在只有少数几个值(如
BOOLEAN类型的is_active)的列上创建索引,因为数据库扫描少量值比使用索引更快。
5.如果我没有创建索引,PGSQL会怎么处理呢?
核心机制:全表扫描 (Full Table Scan)
如果您没有为查询条件(WHERE 子句)中使用的列创建索引,PostgreSQL 就会采用最直接、最基础的方式来查找数据:全表扫描 (Full Table Scan),在 PostgreSQL 的术语中也常称为 顺序扫描 (Sequential Scan)。
1. 顺序扫描的工作原理
顺序扫描的流程非常简单粗暴:
- 从头开始: 数据库从表的第一个数据块开始。
- 逐行读取: 逐一读取表中的每一行数据。
- 逐一检查: 对读取的每一行数据,检查它是否符合
WHERE子句中定义的条件。 - 直到结束: 一直到表的最后一行数据块被读取完毕。
2. 性能后果
- 小表无碍: 如果表非常小(例如只有几百行或一页数据),顺序扫描通常比索引扫描更快,因为省去了读取和遍历索引结构的开销。
- 大表是灾难: 当表变得非常大(数百万或数十亿行)时,顺序扫描意味着数据库必须将整个表从磁盘加载到内存中进行检查。这会导致巨大的磁盘 I/O,严重拖慢查询速度,并消耗大量的系统资源。
3. 隐式索引的例外情况
您可能认为您没有创建索引,但实际上可能存在:
- 主键(PRIMARY KEY): 在 PostgreSQL 中,创建主键时,系统会自动为其创建唯一 B-tree 索引。
- 唯一约束(UNIQUE): 创建
UNIQUE约束时,系统也会自动创建唯一 B-tree 索引。
因此,即使您没有手动写 CREATE INDEX,但如果您的 WHERE 条件是基于 user_id(主键)或 email(唯一约束)进行查询,PostgreSQL 仍然会使用索引扫描。
4. 如何验证 PostgreSQL 的处理方式?
您可以使用 PostgreSQL 的 EXPLAIN 命令来查看查询规划器为您的 SQL 语句选择了哪种执行方案:
xxxxxxxxxx11EXPLAIN SELECT * FROM big_users WHERE username = 'alice';| 场景 | EXPLAIN 结果中的 -> 行 | 意味着什么? |
|---|---|---|
| 无索引 | -> Sequential Scan on big_users | PostgreSQL 将从头到尾读取整个表。 |
| 有索引 | -> Index Scan using idx_users_username on big_users | PostgreSQL 发现并使用了名为 idx_users_username 的索引。 |
总结: 索引扫描是一种“精确打击”,而顺序扫描是一种“地毯式轰炸”。对于大型表上的过滤操作,如果 PostgreSQL 被迫使用顺序扫描,查询性能会非常差,这也是 DBA 必须关注索引覆盖率的原因。
10. 事务
1. 事务的定义和目的
A. 定义 (Definition)
事务是一系列数据库操作(例如 SELECT, INSERT, UPDATE, DELETE)的集合,这些操作被视为一个不可分割的逻辑工作单元。
B. 目的 (Goal)
事务的根本目的是确保数据库在任何时候都处于一致且有效的状态。
类比:银行转账
当您从账户 A 转账 100 元到账户 B 时,数据库必须执行两个操作:
- A 账户余额
-100元。 - B 账户余额
+100元。
这两个操作必须要么全部成功,要么全部失败。如果在第 1 步成功后,第 2 步失败(例如网络断开),那么事务必须撤销第 1 步的操作,恢复到转账前的状态。
2. 事务的核心命令
在 PostgreSQL 中,您可以使用以下命令显式地控制事务:
| 命令 | 作用 | 结果 |
|---|---|---|
BEGIN 或 START TRANSACTION | 开始一个事务。 | 告诉数据库,接下来的所有 SQL 语句都属于同一个逻辑工作单元。 |
COMMIT | 提交事务。 | 永久保存事务中的所有更改到数据库。更改对其他用户立即可见。 |
ROLLBACK | 回滚事务。 | 撤销自 BEGIN 以来在事务中所做的所有更改。数据库恢复到事务开始前的状态。 |
示例流程:
SQL
xxxxxxxxxx131BEGIN;23-- 1. A 账户扣款4UPDATE accounts SET balance = balance - 100 WHERE account_id = 'A';56-- 2. B 账户加款7UPDATE accounts SET balance = balance + 100 WHERE account_id = 'B';89-- 如果两个操作都成功,则提交10COMMIT;1112-- 如果出现错误,则回滚13-- ROLLBACK;
3. 事务的四大特性 (ACID)
任何可靠的数据库系统都必须保证其事务满足 ACID 四大特性:
A. 原子性 (Atomicity)
- 定义: 事务是最小的执行单位,要么所有操作全部完成,要么全部不完成(即回滚)。
- 类比: 扔骰子。一旦扔出,点数就是确定的,不能出现“半个”点数。
B. 一致性 (Consistency)
- 定义: 事务执行前后,数据库必须保持一致的状态。
- 保证: 事务不会破坏预定义的规则(如
CHECK约束、FOREIGN KEY外键等)。例如,转账前后,总金额必须保持不变。
C. 隔离性 (Isolation)
- 定义: 多个并发事务相互独立,互不干扰。一个事务对数据的修改在提交之前,对其他事务通常是不可见的。
- 保证: 避免脏读、不可重复读和幻读等并发问题。
📌 注意: 隔离性不是绝对的,PostgreSQL 提供了不同的隔离级别来平衡性能和数据准确性。
D. 持久性 (Durability)
- 定义: 一旦事务被
COMMIT提交,它对数据库所做的更改就是永久性的。 - 保证: 即使发生系统崩溃、电源故障等意外情况,已提交的数据也不会丢失(通过 WAL 日志实现)。
4. 隔离级别 (Isolation Levels)
隔离级别决定了事务的隔离程度。PostgreSQL 默认使用 Read Committed (读已提交) 隔离级别,但支持以下四种标准级别:
- Read Committed (读已提交 - 默认): 只能看到已提交事务所做的更改。
- Repeatable Read (可重复读): 保证在事务执行期间,多次读取同一行数据的结果始终相同。
- Serializable (串行化): 最高的隔离级别,保证并发执行的事务结果与串行执行(一个个执行)的结果完全一致,彻底避免所有并发异常。
您可以通过 SET TRANSACTION ISOLATION LEVEL [级别] 命令来设置当前事务的隔离级别。
5. 一个prisma案例
我们将使用一个简单的场景:从账户 A 转账到账户 B。
1. 假设的 Prisma Schema (模型)
我们假设您有一个 Account 模型,包含余额:
xxxxxxxxxx51model Account {2 id Int @id @default(autoincrement())3 name String4 balance Decimal5}2. TypeScript/JavaScript 事务代码
xxxxxxxxxx581import { PrismaClient, Prisma } from '@prisma/client';23const prisma = new PrismaClient();45/**6 * 模拟银行转账操作,使用交互式事务保证原子性。7 * @param fromId 转出账户 ID8 * @param toId 转入账户 ID9 * @param amount 转账金额10 */11async function transferMoney(fromId: number, toId: number, amount: number) {12 13 // 核心:使用 $transaction 开启一个交互式事务14 try {15 const result = await prisma.$transaction(async (tx) => {16 17 // 1. 检查转出账户余额18 const fromAccount = await tx.account.findUnique({19 where: { id: fromId },20 select: { balance: true, name: true },21 });2223 if (!fromAccount) {24 throw new Error(`账户 ID ${fromId} 不存在。`);25 }2627 if (fromAccount.balance < amount) {28 // 如果余额不足,抛出错误,事务将自动回滚 (ROLLBACK)29 throw new Error(`转账失败:账户 ${fromAccount.name} 余额不足。`);30 }3132 // 2. 转出账户扣款33 await tx.account.update({34 where: { id: fromId },35 data: { balance: { decrement: amount } },36 });3738 // 3. 转入账户加款39 await tx.account.update({40 where: { id: toId },41 data: { balance: { increment: amount } },42 });4344 // 如果代码执行到这里,事务将自动提交 (COMMIT)45 return { success: true, message: `成功从 ${fromAccount.name} 转账 ${amount}。` };46 });4748 console.log("事务成功:", result);49 50 } catch (error) {51 // 捕获到任何错误,表示事务已自动回滚52 console.error("事务失败,已回滚:", (error as Error).message);53 }54}5556// 示例调用 (假设账户 1 余额 500,账户 2 余额 200)57// transferMoney(1, 2, 150); // 成功转账58// transferMoney(1, 2, 1000); // 失败,自动回滚简单点说,就是在prisma.$transaction里面正常执行操作就行了。虽然简单,但是却保证了ACID特性。
11. 并发
这节课的内容属于原理,知道即可。
核心机制是 MVCC (Multi-Version Concurrency Control),即多版本并发控制。
MVCC 是 PostgreSQL 处理并发事务和保证隔离性的基石。
1. 核心机制:MVCC (多版本并发控制)
A. 定义
MVCC 是一种并发控制技术,它允许数据库中同时存在数据的多个版本。当事务需要读取数据时,它不会阻止其他事务写入同一行数据。
B. 传统锁 vs. MVCC
| 特性 | 传统锁机制 (如 MySQL MyISAM) | PostgreSQL (MVCC) |
|---|---|---|
| 读取操作 | 读取时可能需要对数据行加锁(共享锁),阻止写入。 | 读取永远不会阻塞写入,写入也永远不会阻塞读取。 |
| 数据状态 | 任何时刻数据只有一个版本。 | 数据的多个历史版本可以同时存在。 |
| 并发性 | 低,读写操作相互干扰。 | 高,读写操作可以高度并发。 |
2. MVCC 的工作原理:数据快照
PostgreSQL 的 MVCC 主要依赖于事务 ID 和数据可见性规则:
数据多版本: 当一行数据被更新时,PostgreSQL 不会直接覆盖旧数据,而是创建该行数据的新版本(称为元组,Tuple),并将旧版本标记为过期。
内部 ID: 每一行数据都有隐藏的系统列,最重要的两个是:
xmin:创建该行版本的事务 ID。xmax:删除或更新该行版本的事务 ID。
事务快照 (Snapshot): 当一个事务启动时,PostgreSQL 会为它创建一个“快照”,记录当时所有已提交和未提交事务的状态。
可见性判断: 事务在查询数据时,只查看那些在自己的快照时间点已经提交,并且其
xmin小于或等于自己的快照 ID 的数据版本。
示例: 事务 A 正在读取数据,此时事务 B 更新了同一行。事务 A 看到的仍然是数据更新前的旧版本,因为它不满足事务 A 快照的可见性要求。事务 B 提交后,事务 C 才能看到新版本。
3. MVCC 的关键优势
- 非阻塞读取 (Non-Blocking Reads): 这是 MVCC 最大的优点。读取数据不需要加锁,因此读取操作不会等待写入操作完成,极大提高了并发读的性能。
- 实现隔离级别: MVCC 是实现读已提交 (Read Committed) 和 可重复读 (Repeatable Read) 等隔离级别的底层基础。通过控制事务的快照范围,数据库可以精确地控制事务能看到哪些数据版本。
4. MVCC 的成本:VACUUM (吸尘器) 维护
MVCC 允许多个数据版本共存,但也带来了维护成本:
- 死元组 (Dead Tuples): 每次数据更新或删除后,旧版本的数据仍然留在磁盘上,它们被称为“死元组”。
- 清理需求: 死元组会浪费磁盘空间,并可能减慢全表扫描的速度。
- VACUUM 进程: PostgreSQL 必须周期性地运行 VACUUM 进程,这个进程负责清理并回收这些死元组占用的磁盘空间,使之可以重新用于新数据。
如果 VACUUM 运行不及时,数据库的性能和磁盘空间占用都会恶化。通常,PostgreSQL 的 autovacuum 守护进程会负责自动执行这项维护工作。
总结: PostgreSQL 的并发是基于 MVCC 机制实现的,它通过管理数据的多个版本来避免读写之间的锁竞争,从而实现了高并发和可靠的事务隔离。但这种机制需要定期的 VACUUM 清理来保证性能。